The memory management strategies for multiprogramming systems described in the previous lesson were based on two assumptions:
These seemed like obvious assumptions when multiprogramming was first introduced. However, as programs became larger and as systems started to load larger numbers of processes at the same time, these primitive memory management systems began to break down.
In the 1970s, most computer systems began to switch to a memory management system called virtual memory in which both of these assumptions were violated. Virtual memory is based on the observation that at any given time, a process is only using a small fraction of its code and data. A process which may consist of tens of thousands of lines of code might only be running in a few functions. In fact, a substantial fraction of most real world code consists of error handling routines which are seldom used.
Recall the principles of spatial and temporal locality discussed last week. These two principles also apply to virtual memory.
The idea behind virtual memory is that physical memory is divided into fixed size pages. Pages are typically 512 to 8192 bytes, with 4096 being a typical value. Page size is virtually always a power of two, for reasons to be explained below. Loadable modules are also divided into a number of page frames. Page frames are always the same size as the pages in memory.
Pages frames are loaded into memory only when they are needed. Adjacent page frames are not necessarily loaded into adjacent pages in memory. At a point in time during the execution of a program, only a small fraction of the total pages of a process may be loaded.
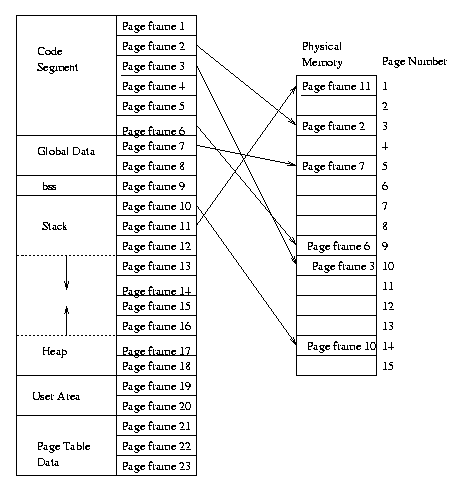
Note that there are two kinds of addresses (or two address spaces), virtual addresses and real addresses. Virtual addresses, also called logical addresses, are program generated. In a system without virtual memory, a physical address and a logical address are the same; the virtual address is placed on the address bus directly because it refers to a physical address in main memory. On systems with virtual memory, there is a mapping between virtual addresses and real addresses. In the above figure, supposed that code for the next instruction to be executed is in page frame 3. The running program only knows the virtual address. Rather than putting the virtual address directly on the address bus, the system sends this address to the Memory Management Unit or MMU. The MMU provides this mapping between virtual addresses and physical addresses. In the example above, this mapping would convert a virtual address in page frame 3 to a real address in page 10. The data structure which contains this mapping is called a page table.
It is possible that a process might access a page which is not in memory. For example, suppose that the process tries to access data in page frame 8. The MMU will determine that this page is not loaded, and this will generate a page fault. A page fault is an interrupt. The handler for a page fault locates the needed page frame on the disk, copies it to a page in memory, and updates the page table, telling it where the page frame is loaded. Control then returns to the process.
When a program first starts running, it will generate a number of page faults. Suppose
that the first executable instruction is
MOV A704,AX; copy value at address hex A704 to register AX
This one instruction will generate two page faults. The instruction itself
will be at an address in the code segment and so the page frame which has this
instruction will have to be loaded into memory. Then the page in the
data segment or stack which contains virtual address A704 will have to be
loaded into another frame. However, if the program conforms to the principles
of temporal and spatial locality, subsequent instructions are likely to
be in the same page frame as this instruction and subsequent accesses to data are
likely to be in the same page frame of data.
Structure of the page table
A row of the page table typically has the following fields.
The MMU
When virtual memory was first proposed, many people thought that it would never work because it would be too difficult to implement paging rapidly enough. The page table provides a mapping between the logical (virtual) address and the real address. This mapping has to be very fast, and the page tables can be very large.
Obviously this mapping has to be implemented in hardware. The section of the CPU that provides this service is called the Memory Management Unit (MMU). Note that every memory reference has to go through the MMU.
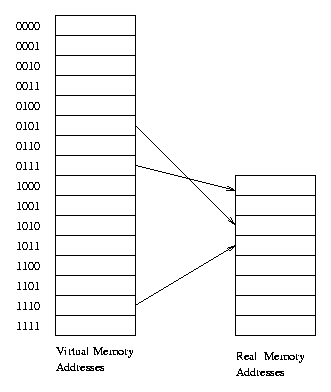
Let's start with a toy implementation to demonstrate
some of the issues that the MMU has to deal with. Suppose a system
has a 16 bit virtual address space (the program addresses range
from 0 .. 64K), but it only has 32K of memory, divided into eight
pages of size 4K. A 16 bit virtual address can be divided into
a 4-bit page reference and a 12-bit offset. Thus, each page and
page frame is 4,096 bytes (212
The page table consists
of 16 entries, one for each possible value of the 4-bit page
field. The offset is simply the address within that page.
For example, the virtual address 0X5068
(0101 0000 0110 0100 in binary)
is divided into two parts. The first four bits refer to the
page (0x5), and the last 12 bits refer to the offset within
that page (0x068) which is 100 in decimal.
The page table has an entry for each logical page, 16 in all, and the four bit page field is an index into the page table.
If the entire page table is loaded into registers, this is trivial to implement in hardware, and performance would be very fast, but it has some serious problems. The obvious one is that most modern systems allow processes to have very large address spaces. An address space of 32 bits per process is typical now. If a page size is 12 bits (4096 bytes, also a typical figure), then the page field has to be 20 bits, so the page table has to have 220 (1,048,57610) entries. This is clearly far too large to load into registers.
Also, keep in mind that each process would have its own page table, and so every time a context switch occurred, the page table for the new process would have to be loaded into the registers, and this would make context switching very slow, far too slow for a typical system which may make a hundred or more context switches per second.
The alternative is to keep the page table in main memory, but this is inefficient because each memory reference now involves two memory references, one to get the appropriate page table entry and one to fetch the actual data. That is not a viable solution.
One solution is to have a multi-level page table. In the above example, a logical address was divided into two fields, a page field and an offset field. With a multi-level page table the logical address is divided into three fields, one for the primary page table, one for the secondary page table, and one for the offset of the address within the page.
Here is an example. A system with a 32 bit logical address field divides such an address into a ten bit field for the first page table, a ten bit field for the second level page table and a 12 bit field for the offset, creating a page size of 212 or 4,096 bytes.
There are potentially 220 entries in the page table, far too many to keep in memory at one time. However, keep in mind that although each process has a potential address space of 232, most processes only use a tiny fraction of this. In particular, when a process is loaded, there is a large chunk of unused memory in the middle of the address space for the stack and the heap to grow into.
Recall that in the page table design described above, each entry in the page table contained a pointer to real memory. In a two level page table, each entry in the first level page table contains a pointer to a second level page table, and the second level page table provides the address of the page in real memory. There are 210 or 1,024 entries in the first level page table, each pointing to a second level page table. The first level page table is always in memory, but only a handful of second level page tables are usually needed.
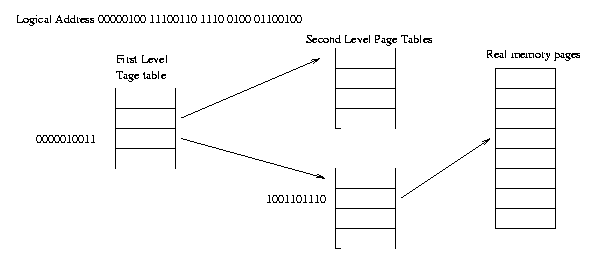
If the 32 bit virtual address is
00000101 11100110 11100100 01100100 or 0x05EAE864
to determine the physical address, this logical address is sent to the MMU,
which extracts the first ten bits 0000010111 to use
as an index to the first level page table. The first level
page table provides a pointer to one of 1,024 second level
page tables (in fact most of these will not exist).
This table is hopefully in memory. The MMU will
extract the second ten bits 1001101110 and use
this as an index to the second level page table, which will
provide a pointer to the actual page in real memory. The last
12 bits 010001100100 will provide the offset in the
page for the actual byte which is requested.
This model is still too slow to be effective. Even if the both of the required page tables are in memory, this now means that one logical memory access would require three memory accesses because the MMU would have to read the first page table and the second page table to be able to generate the physical address.
The solution is Translation Lookaside Buffers or TLBs. These are based on the principles of temporal and spatial locality which most programs conform to. Most processes, no matter how large they are, are usually only executing steps in a small part of the text segment and accessing only a small fraction of the data during any given time short time period. This means that they are accessing only a small number of pages. The idea behind a TLB is that these pages are cached.
The TLB is inside the MMU, and contains pointers to a small number of frequently used pages. Whenever the running program needs to access memory, it first checks to see if the pointer to the page containing that address is stored in the TLB. Most of the time it is, and so the MMU can immediately put the real address on the address bus without having to read any other memory.
Suppose the TLB has slots for 32 pages. Even with this small number, it cannot do a linear search to determine if the page is in the TLB. It needs to search in parallel, and so this has to be implemented in hardware.
Entries in the TLB would look very similar to entries in the actual page table; each record would contain the virtual page number, the physical page number, a valid flag, a dirty bit, and protection information.
The relationship between the TLB, the MMU, and the cache is fairly complicated. Here is a typical arrangement.
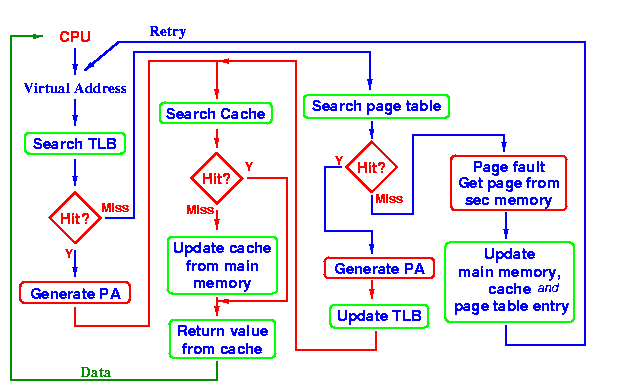
The CPU generates a virtual address. First, the TLB is searched to see if the address of the physical address is cached. If there is a hit, we know the physical address. The next step is to search the cache to see if the value is in the cache. If there is a hit, this value is returned to the CPU. In most cases, both of these queries are hits and so the value can be returned quickly without accessing main memory.
If the TLB does not have a pointer to the page that contains the virtual address, the next step is to search the actual page table. If there is a hit, then we can generate the physical address and so we search the cache to determine if this value is in the cache. We also will add this page to the TLB.
If the page is not in the page table, then a page fault is generated. In this case, the page will be read in from the disk, the page table will be updated, and the TLB will be updated.
Inverted Page Tables
Most page tables are relatively sparse; they contain space for perhaps a million pages, but only a tiny fraction of these pages are actually used by the typical process. Thus, a traditional page table is somewhat wasteful. Also, as 64 bit computers become more common, page tables will be inconceivably huge. The solution is inverted page tables
In a regular page table, there is an entry for each virtual page, in an inverted page table there is an entry for each physical page, so the page table is much smaller. This would not seem to make much sense, because to access a particular virtual address, it would be necessary to search each page in the inverted page table to see if it is there. Of course the system first checks the TLB, and if there is a hit, there is no need to access the page table at all.
An inverted page table uses associative or content addressable memory. Each cell in an associative memory contains a key field and a data field. To search an inverted page table, the system uses a hash function, in which the physical address is passed through a function to generate an index to the appropriate row in the inverted page table. You all remember from your data structures course that a hash function allows very rapid search of large data sets.
Page Replacement Algorithms
When a page fault occurs, the system has to copy a new page frame from disk into a page of memory. This may involve replacing a page which is already loaded. How does the system decide which page to replace? Note that if the page which is being replaced has been modified (the dirty bit is on), it has to be copied to disk. It is important to have an efficient page replacement algorithm, because if the page which is replaced is accessed again soon, the result will be another page fault.
Page faults are time consuming. If the system is generating too many page faults, it is doing little real work. This is a situation called thrashing.
Let's assume that we have perfect knowledge of the page reference stream into the future. The forward distance of a particular page at a particular time is the next place in the stream where that page is referenced again. The forward distance would be 1 if the very next reference was to that page, and infinity if that page will never be referenced again. The optimal page replacement algorithm would be to replace that page which has the highest forward distance, in other words, replace that page which will not be used for the longest time.
Unfortunately, the system has no way of knowing this. However, it is possible to make a reasonable guess about which pages may not be referenced again soon.
One simple and obvious strategy is the not-recently-used algorithm (NRU). This algorithm says to replace a page in memory which has not been accessed recently. Because of the principle of temporal locality, we can assume that a page which has not been referenced recently is unlikely to be referenced soon.
The ideal implementation of the NRU algorithm would be to replace that page which has been least recently used (LRU); i.e. has not been accessed for the longest time. However, it is difficult to implement a pure LRU algorithm because this would require keeping track of how long ago each page was referenced, and the overhead associated with this is far too high to be practical. An approximation of LRU will be discussed below.
It is simple to implement a Not Recently Used algorithm. A row in a page table usually has a flag called the referenced bit. Most systems have a clock which periodically generates an interrupt about once every 20 msec. On each clock interrupt (or similar schedule), the referenced bits of all of the pages in the page table are set to zero. As each page is referenced, its referenced bit is turned on. When a page fault occurs, if an active page needs to be replaced, the system looks for a page where the referenced bit is off, and replaces that page.
This is far from perfect. If a page fault occurs shortly after a clock interrupt, essentially all of the pages will be marked unreferenced, and so the system will have little information about which page to overwrite.
This system is further complicated by the fact that if the dirty bit is on, the page has to be copied to disk. In this case, a page fault results in both a read-from-disk operation and a write-to-disk operation. Thus, a variant of this NRU strategy is to look first for a page where both the referenced bit and the dirty bit are off, and it only replaces a page with the dirty bit on if there are no pages with both bits off. Of course this requires additional overhead because the entire page table has to be searched.
Another low overhead strategy is the First In First Out (FIFO) page replacement algorithm. In this case, the system keeps track of the load time for each page, and it replaces that page with the longest time in memory. This can be easily implemented by putting each new page at the tail of a list in memory, and removing pages from the head.
The FIFO algorithm should be included in this list for completeness, but it is not used in practice. There is no particular reason to assume that the page which was loaded longest ago is less likely to be accessed soon than a page which was just loaded.
We can improve on the NRU algorithm. The text describes a second chance algorithm and a clock algorithm, but the latter is just an implementation of the former. The clock algorithm keeps all of the current pages in a circular list. There is a pointer which moves around this list like the hand of a clock. When a page fault occurs, the system examines the page that the hand is currently pointing to. If the referenced bit is off, this page is replaced in memory (copying the contents back to disk if the dirty bit is on). If the referenced bit is on for that page, it is set to off and the hand continues around the list. This continues until it finds a page where the referenced bit is off. The algorithm is guaranteed to find such a page, because the list is circular, and the hand will eventually get back to the page where it started, and this page will have the referenced bit off.
It goes without saying that the referenced bit is turned on whenever a page is referenced.
This algorithm has an advantage over the NRU algorithm, because when it finds a page frame with the referenced bit off, it can be certain that this page has not been referenced in one full sweep across all of the pages, whereas with the NRU algorithm, if the system finds a page with the reference bit off, there is no guarantee regarding how long ago it was referenced, only that it has not been referenced since the last clock interrupt.
The clock algorithm or variants of it are used in many real operating systems.
It was stated above that the Least Recently Used (LRU) algorithm would be very efficient, but that it would be difficult to implement in practice. The text talks about two ways to implement LRU in hardware.
One method is for the system to maintain a counter which is incremented each time any instruction is accessed. The row of data in the page frame needs to maintain room for this counter. Whenever a particular page is referenced, the counter is incremented and the value is copied to the page frame.
When it is time to replace a page in memory, the system checks this value in each page and replaces that page where the value is the lowest.
Here is an example. Suppose that the value of the counter at the start of the scenario is 1000 (in practice, the counter should be very large, the text suggests 64 bits). There are eight pages in memory, numbered one to eight. Here is a string of page references.
6, 7, 3, 8, 8, 1, 4, 2, 5, 6, 1
After executing this string, here is the value of the counter for each of the eight page frames.
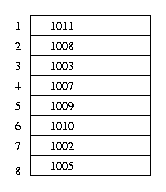
If a page fault occurred at this point in time, and one of these eight pages had to be replaced, the system would look for the lowest value of the counter, see that it was page 7, and it would replace that page.
This algorithm can only be implemented if there is hardware support for it in the MMU, and few if any hardware developers have implemented such an algorithm.
A close approximation of the LRU algorithm can be implemented entirely in software. The text refers to this as Not Frequently Used (NFU) with aging. It works like this. Each page has a counter associated with it. Recall that operating systems have a clock interrupt which occurs roughly every 20 msec. At each clock interrupt, each counter is right shifted by one bit (this is equivalent to dividing by 2. The least significant bit is lost). If the page has been referenced since the last interrupt, the most significant bit of the counter is set to one, otherwise it is set to zero. Then all of the referenced flags are set to zero.
Here is an example. There are six pages in memory, and the counter is eight bits. (Eight bits is usually enough). During each time slice (the period of time between clock interrupts), the following pages are referenced. For example, during the first time slice, pages 2 and 4 were referenced, the others were loaded but not referenced.
| 1 | 2,4 |
| 2 | 1,2,3,4 |
| 3 | 2,3,4,5,6 |
| 4 | 1,2 |
| 5 | 1,2,5,6 |
| 6 | 2 |
| 7 | 1,2,6 |
| 8 | 1,2,5 |
| 1 | 11011010 (218) |
| 2 | 11111111 (255) |
| 3 | 00000110 (6) |
| 4 | 00000111 (7) |
| 5 | 10010100 (148) |
| 6 | 01010100 (84) |
Note that any page which was referenced in the last clock cycle will have a higher value than a page not so referenced, because its most significant bit will be one, and the most significant bit of any page not referenced in the last cycle will be zero. Likewise, any page referenced in the past two cycles will have a higher value than a page which has not been referenced in the past two cycles, and so on.
Working Sets All of the above models of paging use demand paging. In demand paging, a page is only loaded when it is needed, and a page fault always loads exactly one page. When a process is first created, none of its pages are in memory, and so there will always be a number of page faults when a process starts. After a while, enough pages will be loaded into memory so that the process runs for long periods with few page faults. The set of pages which need to be in memory in order for the program to run for an extended period with few page faults is called the working set.
Operating systems which are running at or near capacity will swap out processes, that is, remove all of their pages from memory and remove the job from the running queue. At some point a swapped out job will be swapped back in, that is, returned to the running queue. If the system is using demand paging, such a job will again generate a number of page faults before having enough pages in memory to run. Thus, it would make sense to keep track of the pages of a process which were in memory when the job was swapped out, and when the job was swapped back in, restore all of these pages to memory before starting to run the job. Loading pages before they generate a page fault is called prepaging, and this model is called the working set model because it restores the entire working set of a process before running it.
This is more complicated than it seems. The operating system needs to keep track of which pages have been recently accessed. It is possible, indeed likely, that a process may have pages loaded which it has not accessed for a while, but which have not been replaced. These pages should not be considered to be a part of the working set.
We can define the working set w(k,t) at time t as the set of pages that have been referenced by a particular process within the past k memory references. Up to a point, as k increases, the size of the working set increases, but this function levels off quickly.
In order to implement this, the system would need to update a register at each memory reference, and this is far too costly to be done even in hardware. However, it is possible to have a reasonable simulation. A field for time of last use is associated with each page (although this cannot be kept entirely current). As with other page replacement algorithms, each page also has a referenced bit. At each clock tick (about once every 20 msec), the system clears this bit (sets it to zero), and each page reference sets it to one.
All operating systems keep track of the total running time of a process. When a page fault occurs, the system checks all of the pages associated with the current process. If the referenced bit is on, meaning that the page has been referenced since the last clock tick, the time of last use field is updated to the current value of the total run time of the process. If the referenced bit is zero, the value in time of last use field is compared to the current total time value, and if the difference is greater than some value, tau, this page is removed.
Here is an example. At an instant in time, the currently running process has six pages in memory. The total running time of the process is now 1000 msec (this value is always an approximation, since it is only updated at clock interrupts). The value of tau, set by the system, is 50 msec, meaning that pages which have not been referenced in the past 50 msec of run time for that process are candidates to be replaced because they are no longer in the working set. Here are the values of the six pages when a page fault occurs. Clearly the page table would have other data as well, but I only show the data relevant to this algorithm.
| Page number | Time of last use | Referenced flag |
|---|---|---|
| 1 | 980 | 1 |
| 2 | 980 | 0 |
| 3 | 960 | 0 |
| 4 | 980 | 1 |
| 5 | 930 | 1 |
| 6 | 940 | 0 |
The system needs to find a page to replace. The first page has been referenced since the last clock interrupt, so it is clearly not a candidate for replacement. Its Time of last use field is updated to 1000 (the current running time value). The second page has not been referenced in this clock cycle, but the curren time (1000) minus its time of last use (980) is less than tau (20 is less than 50), so it is not a candidate for removal. The same is true of the third page. Pages 4 and 5 have been recently referenced, so their time of last use field is updated to 1000. Page six has not been referenced since the last clock tick (its referenced bit is zero) and the current time minus its time of last use is 60 msec, which is greater than tau, so it is no longer in the working set and it is a candidate for replacement.
This algorithm works well, but there is a lot of overhead associated with it because at each page fault, every page associated with that process has to be examined and possibly updated. This algorithm can be combined with the clock algorithm to get an efficient page replacement strategy which is widely used in practice.
In this algorithm, the pages associated with a process are kept in a circular list. Each page has a referenced bit, a modified bit (dirty bit), and a time of last use field as well as a pointer to the physical page address. At each page fault, the list is searched to find a suitable candidate for replacement. Searching starts where it ended at the last page fault (Picture the hand of a clock). The algorithm differs from the above in that not all pages are searched, searching stops when a suitable page for replacement is found. Also, if the page is not in the working set but the modified bit is on, meaning that the page cannot be replaced until its new values are written to disk, rather than performing the write immediately, the write to disk is scheduled and the hand moves on, looking for a better candidate page.