This assignment is to be done either individually or in pairs. Do not show your code to any other group and do not look at any other group's code. Do not put your code in a public directory or otherwise make it public. However, you may get help from the TAs or the instructor. You are encouraged to use the LMS Discussions page to post problems so that other students can also answer/see the answers.
The goal of this assignment is to implement a Map Reduce framework using the actor model. You will then use your Map Reduce framework to calculate document word frequencies. For this assignment, you must use an actor language such as SALSA or Erlang.
Hint: First solve the problem using local concurrency (all actors in the same machine), and when your concurrent program is working, then convert your program to run in a distributed environment (actors in different machines.)
The Map Reduce framework expects a user-defined map and reduce function. The map function must take a key-value pair as its argument and must return a list of key-value pairs. The reduce function must take as its argument a pair whose first item is a key and second item a list of values. The reduce function must return a pair consisting of a key followed by a list of values.
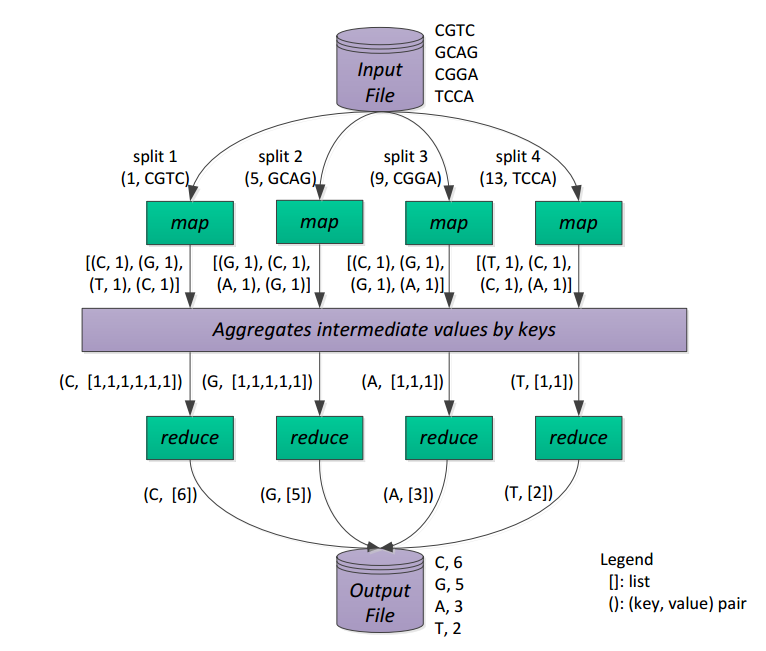
The Map Reduce framework takes the user-defined map and reduce functions and goes through three phases: a Map phase, a Shuffle phase, and a Reduce phase. In the Map phase, an input file is split into multiple key-value pairs, which are given to Mapper actors who call the user-defined map function on the provided input. In the Shuffle phase, the Mappers sends the map results to Shuffler actors, whose job is to aggregate the given list of key-value pairs into a key along with a list of values that correspond to the key. Finally, in the Reduce phase, each Reducer actor is sent a key along with a list of values and performs reduce to generate another list of values. In the end, the reducer results are written to an output file.
Here is a figure illustrating a DNA sequence character counting problem solved with the Map Reduce framework:
Figure source: Developing Elastic Software for the Cloud, Encyclopedia on Cloud Computing. Wiley, 2015.
For this assignment, we will assume that the input and output of the Map-Reduce framework are both text files. The input file contains a list of key-value pairs, each on its own line with the key and the value(s) separated with a single tab ('\t'). The output file is to contain a list of reduced results, each on its own line consisting of the key, then a tab, then the list of values separated with single tabs. See a sample input file and a sample output file for the illustrated DNA sequence character counting problem.
After implementing the Map Reduce framework, you will use it to solve the document word frequency calculation problem. The input file contains a list of key-value pairs, each of which contains a key that is the name of the document and values which are the words. Words exclusively consist of alphabetical characters. The output file should contain a list of word frequency lines in the following format:
[word][tab]([doc1],[wf1])[tab]([doc2],[wf2]) ...that is, the word, followed by a tab ('\t'), followed by a list of document-word frequency pairs separated with single tabs, each pair is put in a pair of parentheses and has a comma in between. See a sample input and a sample output file.
Please clearly specify in your README file how to run your distributed framework, including how to specify map and reduce functions, the machines where actors are to run, and how to change the number of actors in your framework, if deviating from the language-specific instructions below.
A startup package for the Map Reduce framework is given in pa2start.zip, which contains a sample usage of the framework (once it is implemented) for the sample DNA sequence character counting problem. Make sure your Map Reduce framework works with this problem before trying the word frequency problem.
Your concurrent program should be run in the following manner:
$ salsac mapreduce/* $ salsa mapreduce.MapReduceProblem [input] [output] [mappers] [shufflers] [reducers]and your distributed program should be run in the following manner:
$ salsac mapreduce/* $ salsa mapreduce.MapReduceProblemD [input] [output] [mappers] [shufflers] [reducers] [theaters]where
input specifies an input file name,
output specifies an output file name,
mappers,
shufflers, and
reducers specify the number of actors to use for each map
reduce phase, and theaters is a name server and theater
description file.
See a sample name server and theaters description file, the first line of which specifies the name server location and each of the remaining lines specifies a theater location.
salsac and salsa are UNIX aliases or Windows
batch scripts that run java and javac with
the expected arguments: See .cshrc
for UNIX, and salsac.bat
salsa.bat
for Windows.
[host0:dir0]$ wwcns [port number 0] [host1:dir1]$ wwctheater [port number 1] [host2:dir2]$ wwctheater [port number 2] ...where
wwcns and wwctheater are UNIX aliases
or Windows batch scripts: See .cshrc
for UNIX, and wwcns.bat
wwctheater.bat
for Windows.
mapreduce directory should be visible in directories:
host1:dir1 and host2:dir2.
Then, run the distributed program as mentioned above.
MapReduceProblem behavior should be in a relative path mapreduce/MapReduceProblem.salsa, and should
start with the line module mapreduce;.m1(...);m2(...); does not imply m1 occurs before m2.m(...)@n(...);, n is processed after m is executed, but not
necessarily after messages sent inside m are executed. For example, if inside m, messages
m1 and m2 are sent, in general, n could happen before m1 and m2.
Your implementation must have a start function that takes the following arguments:
Your start function should be called, for example, as
follows:
start("input_file.txt","output_file.txt",fun dna_char_count:map/1,
fun dna_char_count:reduce/1,4,2,2,
['workplace1@127.0.0.1','workplace2@127.0.0.1','workplace3@127.0.0.1'])
In this example, dna_char_count is the problem-specific module that implements map and reduce and the 1 represents
the number of input arguments for both map and reduce.
Your problem-specific map and reduce functions should be implemented in a separate module from the
map-reduce framework.
Below is a sample implementation of map and reduce for counting characters in a DNA sequence:
-module(dna_char_count).
-export([map/1,reduce/1]).
map({_,Value}) -> lists:map(fun(X) -> {X,1} end, Value).
reduce({Key,Values}) -> {Key,[lists:foldl(fun(V,Sum) -> Sum + V end, 0, Values)]}.
The above example can be found here.
When writing distributed Erlang code, you will need to create nodes
with a shared cookie and establish communication between nodes. The
shared cookie is just an atom that is used to restrict communication
to nodes having the same cookie.net_kernel:connect_node/1 can be used
to establish communication between nodes. It is possible to use
spawn/4 to create new actors on a remote node.
To start a node named workplace1@127.0.0.1 with
cookie mapreduce, you may use the command:
$ erl -noshell name workplace1@127.0.0.1 -setcookie mapreduce
Due Date: Thursday, 10/29, 7:00PM
Grading: The assignment will be graded mostly on correctness, but code clarity / readability will also be a factor (comment, comment, comment!).
Submission Requirements: Please submit a ZIP file with your code, including a README file. Your ZIP file should be named with your LMS user name(s) as the filename, either userid1.zip or userid1_userid2.zip. Only submit one assignment per pair via LMS. In the README file, place the names of each group member (up to two). Your README file should also have a list of specific features / bugs in your solution.