 Client-Server Architecture
Client-Server Architecture
A NETWORK SERVER APPLICATION THAT can handle only one client at a time isn’t very useful. For example, consider an IRC chat application wherein only one client could connect to an IRC chat server at a time. How much fun would it be to chat with yourself? A server is typically required to handle multiple clients simultaneously.
Handling multiple clients at the same time requires solving several problems. The first issue is allowing multiple clients to connect and stay connected simultaneously. In this chapter, we cover three different general strategies for handling this: multiplexing, forking, and threads. The second issue is one of resources and how to efficiently utilize the memory and processor(s) available. The final issue is keeping the server responsive to each of the clients—in other words, not allowing a client to monopolize the server at the expense of the other connected clients. This is especially important when large amounts of data are to be transferred between the client and server.
This chapter will explain the various strategies available to handle multiple clients. In addition, we’ll build servers of each type. We’ll start off with a client test program.
Client Test ProgramA server isn’t much good without a client program to connect to it. In this chapter we’ll look at and implement several types of servers. To see how they work we’ll use a client test program. This will help us see how each server type handles multiple clients.
To test a server you’ll need to open two xterm windows. In the first window, execute the server that you wish to test. In the second window, execute the client test program. You should see output in both the server and client windows.
Here’s our test client program, client.c. We’ll use it to test the various server examples throughout this chapter. First, we include the needed system header files:
/* client.c *
/
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
We’ll use the fork() system call to generate a number of child processes to simulate multiple clients connecting to the server at the same time. This is the forward declaration of the process function:
void child_func(int childnum);
This is our main() function. We check the command line to see how many child processes to create.
int main(int argc, char *argv[])
{
int nchildren = 1;
int pid;
int x;
if (argc > 1) {
nchildren = atoi(argv[1]);
}
Next, we loop and create the specified number of children. We will look at this later, but if fork() returns 0, then it has returned in the child process, so we call our child function.
for (x = 0; x < nchildren; x++) {
if ((pid = fork()) == 0) {
child_func(x + 1);
exit(0);
}
}
Once we’ve created all of the children, the parent process waits for them to finish before returning.
wait(NULL);
return 0;
}
Next, we create our child function. This is where we connect to the server.
void child_func(int childnum)
{
int sock;
struct sockaddr_in sAddr;
char buffer[25];
We create our client socket and bind it to a local port.
memset((void *) &sAddr, 0, sizeof(struct sockaddr_in));
sAddr.sin_family = AF_INET;
sAddr.sin_addr.s_addr = INADDR_ANY;
sAddr.sin_port = 0;
sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
bind(sock, (const struct sockaddr *) &sAddr, sizeof(sAddr));
Then we attempt to connect to whichever server is running on the local machine.
sAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
sAddr.sin_port = htons(1972);
if (connect(sock, (const struct sockaddr *) &sAddr, sizeof(sAddr)) != 0) {
perror("client");
return;
}
Once connected, we send some characters to the server and read what the server sends back. We also insert some pauses, using sleep() to keep the clients from connecting and disconnecting so quickly that we don’t have more than one connected to a server at the same time.
snprintf(buffer, 128, "data from client #%i.", childnum);
sleep(1);
printf("child #%i sent %i chars\n", childnum, send(sock, buffer,
strlen(buffer), 0));
sleep(1);
printf("child #%i received %i chars\n", childnum,
recv(sock, buffer, 25, 0));
Finally, we close the connection and return.
sleep(1);
close(sock);
}
The test client can be compiled with the following command:
$>gcc -o client client.cThis runs the client with five child processes, each connecting to the server.
$>./client 5
The first strategy for handling multiple connections that we’ll discuss is multiplexing. Multiplexing is a way of handling multiple clients in a single server process. The application allows clients to connect to the server and adds them to a watch list. This watch list is just an array of socket descriptors. Then the operating system tells the application which clients (if any) need to be serviced or if a new client has established a connection.
As an example, think of a restaurant with only one waiter. The waiter is responsible for attending to all the tables at the same time. As customers come in and are seated, the waiter adds them to a mental list of tables to check on. Then, when a table needs attention, he attends to it. Of course, only one table may be serviced at a time, and the possibility exists of a single table using up all the waiter’s time.
The select() Functionselect() is a system function that allows us to specify a set of descriptors (sockets, in this case) that we are interested in. It is worth noting that select()works with any descriptor, including files, pipes, FIFOs, etc. The system puts our program to sleep, polls the sockets for activity, and wakes the program when an event occurs at one of the sockets. This keeps us from writing a busy loop and wasting clock cycles. The select() function prototype looks like this:
#include <sys/select.h>
int select(int n, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
The first parameter specifies the highest numbered descriptor (plus 1) to watch in the three sets. It is important to remember that you must add 1 to the highest numbered descriptor in the sets. The reason is that the watch lists are linear arrays of bit values, with 1 bit for every available descriptor in the system. What we are really passing to the function is the number of descriptors in the array that it needs to copy. Since descriptors start at 0, the number we pass is the largest descriptor number plus 1.
Next, we provide three descriptor sets. The first set contains descriptors to be watched for read events, the second for write events, and the third for exceptions or error events. Finally, we provide a timeval that specifies a timeout. If no event occurs in any of the sets before the timeout, then select() returns a 0. We can also specify a null pointer for the timeoutparameter. In this case, the call will not return until an event happens on one of the watched descriptors. Otherwise, it returns the number of descriptors in the three sets.
It is important to note that select() does modify the descriptor sets that are passed to it. Upon return, the sets will contain only those descriptors that had some activity. To call select multiple times, we must retain a copy of the original sets. Other than a socket error, if any error occurs, then –1 is returned.
Four macros are provided to help deal with the descriptor sets. They are FD_CLR , FD_ISSET , FD_SET , and FD_ZERO . Each takes a pointer to a variable type fd_set . Except for FD_ZERO , each takes a descriptor as well. It is important to note that the behavior of these macros is undefined if you pass in a descriptor that is less than zero or greater than FD_SETSIZE. The macros are prototyped as follows:
-
void FD_SET(int fd, fd_set *set)
:
FD_SET
flags a descriptor to be watched.
-
void FD_CLR(int fd, fd_set *set)
:
FD_CLR
resets the flag set to a descriptor.
- int FD_ISSET(int fd, fd_set *set)
: After
select()
returns,
FD_ISSET
determines whether a descriptor is flagged or not.
-
void FD_ZERO(fd_set *set)
:
FD_ZERO
clears the set so that no descriptors are watched.
A flagged descriptor indicates activity at the socket.
Here is a code fragment example of using select() :
int sd; /* our socket descriptor *
/
fd_set sockreadset;
FD_ZERO(&sockreadset);
FD_SET(sd, &sockreadset);
select(FD_SETSIZE, sockreadset, NULL,
NULL, NULL);
if (FD_ISSET(sockreadset))
printf("Socket ready for read.\n");
In this example, the program will wait indefinitely for a read event to occur on the descriptor whose value is specified in sd .
A Multiplexing ServerIn our example, the server uses select() to listen for new connections, check for client disconnects, and read events on existing connections. If a read event occurs on the server’s listening socket, then a new connection is initiated and the server calls accept() to get the new socket descriptor. The new descriptor is then added to the server’s watch set.
On the other hand, if a read event occurs on another socket, then the server calls recvto retrieve any data sent by the client. If no data is received, then the client has disconnected, and the server removes the respective descriptor from the watch set. Otherwise, the data is read and echoed back to the client. Figure 5-1 shows the basic architecture of a multiplexing server.
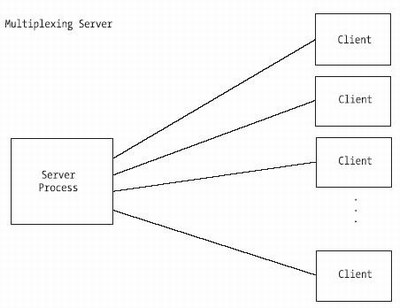
Figure 5-1. Basic architecture of a multiplexing server
Here is the program ( server1.c ) to implement the preceding example:
/* server1.c */
#include <stdio.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(int argc, char *argv[])
Next, we set up the variables that we’ll need. As select() modifies the set passed to it, we use two variables: one to maintain our state and another to interact with the select() function. We need to keep the master set separately:
{
struct sockaddr_in sAddr;
fd_set readset, testset;
int listensock;
int newsock;
char buffer[25];
int result;
int nread;
int x;
int val;
Then we create the listening socket. This is the socket that will listen for incoming connections from the clients.
listensock = socket(AF_INET, SOCK_STREAM,
IPPROTO_TCP);
Afterward, we set the socket option SO_REUSEADDR . While debugging, you’ll be starting and stopping your server often. Linux tends to keep the address and port that was used by your program reserved. This option allows you to avoid the dreaded “address in use” error.
val = 1;
result = setsockopt(listensock,
SOL_SOCKET, SO_REUSEADDR, &val,
sizeof(val));
if (result < 0) {
perror("server1");
return 0;
}
Here, we bind the socket to the listening port. We use the special address INADDR_ANY to specify that we’ll listen on all IP addresses associated with the server:
sAddr.sin_family = AF_INET;
sAddr.sin_port = htons(1972);
sAddr.sin_addr.s_addr = INADDR_ANY;
result = bind(listensock, (struct sockaddr
*) &sAddr, sizeof(sAddr));
if (result < 0) {
perror("server1");
return 0;
}
We put the socket into “listen” mode so that we can accept incoming connections:
result = listen(listensock, 5);
if (result < 0) {
perror("server1");
return 0;
}
We initialize our descriptor set using FD_ZERO . Then we add the listening socket to the set so that the system will notify us when a client wishes to con nect. Connection requests are treated as read events on the listening socket:
FD_ZERO(&readset)
;
FD_SET(listensock, &readset);
Notice that we assign our descriptor set to an alternate variable to be passed to the select() function. As noted previously, this is because select() will alter the set we pass, so that upon return, only those sockets with activity are flagged in the set. Our call to select() signifies that we are interested only in read events. In a real-world application, we would need to be concerned with errors and pos sibly write events. We loop through the entire set of descriptors. FD_SETSIZEis a constant set in the kernel and is usually 1024. A more efficient server implementation would keep track of the highest numbered descriptor and not loop through the entire set. FD_ISSETis used to determine if the descriptor is flagged as having activity. It returns a nonzero value if the supplied descriptor is set as having had activity; otherwise, it returns 0.
while (1)
{
testset = readset;
result = select(FD_SETSIZE, &testset,
NULL, NULL, NULL);
if (result < 1) {
perror("server1");
return 0;
}
for (x = 0; x < FD_SETSIZE; x++) {
if (FD_ISSET(x, &testset)) {
If the activity is on the listening socket, then we accept the new connection and add its socket to our watch set. Otherwise, we read characters from the client. If the number of characters read is less than or equal to zero, then the client is assumed to have closed the connection. We close the connection on our side and remove the descriptor from our watch list. Otherwise, we echo the charac ters to the screen and back to the client.
if (x == listensock)
{
newsock = accept(listensock, NULL,NULL);
FD_SET(newsock, &readset);
} else {
nread = recv(x, buffer, 25, 0);
if (nread <= 0) {
close(x);
FD_CLR(x, &readset);
printf("client on descriptor #%i disconnected\n", x);
} else {
buffer[nread] = '\0';
printf("%s\n", buffer);
send(x, buffer, nread, 0);
}
}
}
}
}
}
The server can be compiled with a command similar to the example client. Figure 5-2 shows a sample of the output obtained on executing the program.
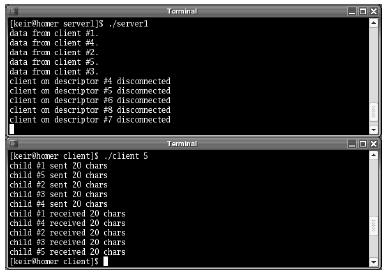
Figure 5-2. Output from a multiplexing server
Notice that, for a brief time, all five clients are connected at the same time.
In the UNIX environment, the traditional way to handle multiple clients is to use the fork() system call. When an application calls fork() , an exact duplicate of the calling program is made, right down to the program counter (PC), and a new child process is started with that copy. Everything (except the parent’s process ID, or PID) is copied. This includes the parent’s heap, stack, data space, and all open descriptors. Then, the system call returns twice: once in the calling program and the next time in the child process. The return value in the calling program is the PID of the new child process, while in the child process it is 0.
This can be a little confusing at first. How can a function that is called once return twice, you ask? If you think carefully about what the fork() call does, though, it is very logical. Calling fork() makes an exact copy of the program. This means that when the copy begins execution, it starts at the exact place the call ing program was, which is the fork() call.
Let’s see, in a little more detail, the consequences of copying descriptors. As mentioned previously, when the child process is created, everything is copied to the child, including all open descriptors. The Linux kernel keeps a reference count for each descriptor. So, when a child is created, the reference count is incremented for each copy. As a result, the client must close the descriptor of the listening socket used by the parent process, and the parent must close the descriptor of the client socket used by the child process. This will become evident on executing the program server2.c . If close()is not called on these sockets, the reference count in the kernel will be wrong, resulting in open or stale connections potentially abusing or exhausting system resources as time goes on.
Using the fork() system call to handle multiple clients has several advantages. First, it’s simple. Creating a new process to handle each client is easy to implement. Second, using a process per client keeps any one client from monopolizing the server, because the Linux kernel will preemptively swap the processes in and out. Third, other child processes won’t be affected if one of the child processes crashes, because the kernel prevents one process from damaging memory in another process.
The fork() system call isn’t without its disadvantages, however. The most notable problem with the multiprocess approach is the lack of shared memory. Over the years, shared memory solutions (like shmget() ) have been made available for multiprocess applications, but it isn’t as elegant as with a threaded approach. shmget()is a system call that allows the allocation of a shared memory segment that can be accessed by multiple processes. The way it works is that the parent process creates a shared memory segment upon startup. Then, as each child is created, it inherits the attachment to the shared memory. Even with the shared memory, access to it must be synchronized with semaphores. Finally, with large programs, significant resources can be used because everything must be copied for each child, resulting in slow performance and potential exhaustion of resources.
CAUTION When using the fork() system call, you must be very careful to not create zombies. Zombies are child processes that occur when the parent process exits without calling wait() or waitpid() on the child process. The kernel keeps the exit information for these child processes until the parent process calls wait() or waitpid() to retrieve it. If the parent exits without retrieving the exit information, the child processes remain in a zombie state. Eventually the kernel will clean them up, but it is best to avoid them in the first place to free up system resources. The simplest way to handle this issue is by trapping the SIGCHLD signal and calling waitpid() . This is demonstrated in the forking server in the next section.
One Process Per Client
The simplest architecture for a multiprocess server is to use one process per client. The server simply waits for a client to connect and then creates a process to handle it. From an application design standpoint, this is much less cumbersome than the multiplexing approach we examined earlier. Each client has a dedicated process, and the client logic flows linearly without worrying about stopping to service other connected clients, as compared to multiplexing, where a single process must deal with all clients simultaneously.
A Forking Server
In the following program ( server2.c ), the initial process waits for a client to connect. It then calls fork() to create a new child process to handle the client. Next, the child process reads the data from the client and echoes it back. Finally, the connection is closed, and the child exits. Meanwhile, the parent process loops back to listen for another connection. Figure 5-3 shows the basic architecture for a multiprocess server.
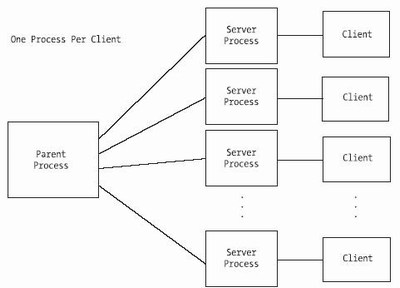
Figure 5-3. Basic architecture for a multiprocess server
The initial section of the code is similar to the earlier program, server1.c :
/* server2.c *
/
#include <stdio.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
To trap the child exits and prevent zombies, we also need the following two header files:
#include <sys/wait.h>
#include <signal.h>
Here’s our signal handler. It simply calls waitpid() for any exited children. The reason we call it in a loop is that there may not be a one-to-one correlation between exited children and calls to our signal handler. POSIX does not allow for the queuing of signal calls, so our handler may be called once when several chil dren have exited and we need to call waitpid() for each one.
void sigchld_handler(int signo)
{
while (waitpid(-1, NULL, WNOHANG) > 0);
}
Next, we declare the variables that we will need.
int main(int argc, char *argv[])
{
struct sockaddr_in sAddr;
int listensock;
int newsock;
char buffer[25];
int result;
int nread;
int pid;
int val;
Then we create the socket that will accept the incoming connections.
listensock = socket(AF_INET, SOCK_STREAM,
IPPROTO_TCP);
Here we set our SO_REUSEADDR option.
val = 1;
result = setsockopt(listensock,
SOL_SOCKET, SO_REUSEADDR, &val, sizeof
(val));
if (result < 0) {
perror(“server2”);
return 0;
}
We then bind it to a local port and all addresses associated with the machine.
sAddr.sin_family = AF_INET;
sAddr.sin_port = htons(1972);
sAddr.sin_addr.s_addr = INADDR_ANY;
result = bind(listensock, (struct sockaddr
*) &sAddr, sizeof(sAddr));
if (result < 0) {
perror("server2");
return 0;
}
Afterward, we put the socket into listening mode to listen for incoming connections.
result = listen(listensock, 5);
if (result < 0) {
perror("server2");
return 0;
}
Before we start looping, we install our signal handler.
signal(SIGCHLD, sigchld_handler);
We then call accept() and allow it to block waiting for connection requests from clients. After accept returns, we call fork() to create a new process. If it returns 0, then we are in the child process; otherwise, the PID of the new child is returned.
while (1) {
newsock = accept(listensock, NULL,
NULL);
if ((pid = fork()) = = 0) {
Once in the child process, we close the listening socket. Remember that all descriptors are copied from the parent process to the child. The child process does not need the listening socket any longer, so we close the child’s reference on that socket. However, the socket will remain open in the parent process. Next, we read characters from the client and echo them to the screen. Finally, we send the characters back to the client, close the socket, and exit the child process:
printf("child process %i created.\n",
getpid());
close(listensock);
nread = recv(newsock, buffer, 25, 0);
buffer[nread] = '\0';
printf("%s\n", buffer);
send(newsock, buffer, nread, 0);
close(newsock);
printf("child process %i finished.\n",
getpid());
exit(0);
}
This line is only reached in the parent process. Since the child process has a copy of the client socket, the parent process closes its reference here to decrease the kernel reference count. The socket will remain open in the child process:
close(newsock);
}
}
The server can be compiled with a command similar to the example client. Figure 5-4 shows sample output obtained on executing the preceding program. The client was run with five child processes.
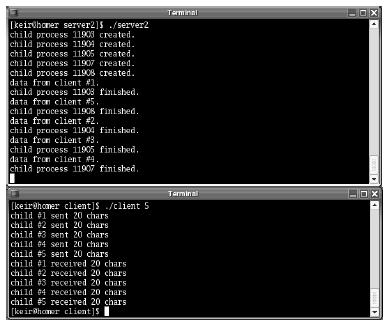
Figure 5-4. Output from a multiprocess server
While the preceding strategy is simple to implement, there is a performance penalty to be paid. Creating a copy of a running process is expensive (in terms of time as well as resources), especially for large applications. As clients start con necting in large numbers, there can be a noticeable delay in launching the child process.
One strategy to mitigate the startup costs for a process is to fork a number of processes into a “process pool” when the application starts. This is called pre-forking, and it restricts all of the costs associated with creating a child process to the initialization section of the application. When a client connects, the process to handle it has already been created. Using this method, accept()is not called in the parent process, but in each child process. Unlike the previous example, the listening socket descriptor will not be closed in the child process. In fact, all of the children will be calling accept()on the same listening socket. When a client connects, the kernel chooses one of the children to handle the connection. Since the child is already running, there is no process creation delay.
Example: Apache Web Server
The original Apache Web Server (prior to version 2), http://httpd.apache.org , uses process pools. However, it takes them one step further by making the process pool size dynamic. In the Apache configuration file, you are able to specify the number of initial children, the maximum number of children, the minimum number of idle children, and the maximum number of idle children.
The initial and maximum number of children is pretty straightforward. Specifying the minimum and maximum number of idle children allows the server to handle sudden spikes in usage. The parent process continually checks on the child processes to see how many are idle. It then terminates extra children or creates new children depending on the settings. Using configuration settings, the server can be finely tuned for maximum performance.
Apache version 2 takes this even a step further by introducing thread pools. Thread pools are similar to process pools in that you generate the handlers to deal with connecting clients during the initialization of the application, but you are creating threads instead of processes. We’ll talk about thread pools in the section “Prethreading: Thread Pools.”
A Preforking Server
In the following program ( server3.c ), the parent server process uses a loop to create the specified number of child processes. On execution, we can pass in the number of children to fork, on the command line. The parent server process then calls wait()to keep it from returning before any of its children. If we don’t insert this call, the parent process will end immediately. Each child then calls accept on the same listening socket and waits for a client connection. When a connection is made, the operating system chooses one of the children to signal using a “first in, first out” methodology. That child receives the data from the client and echoes it back. Finally, the connection is closed, and the child calls accept() again to wait for another client. Figure 5-5 shows the basic architecture for process pools.
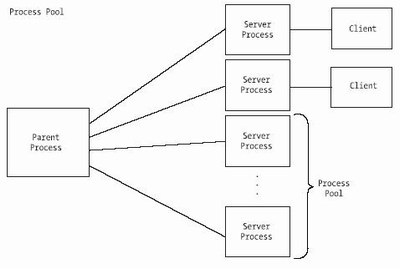
Figure 5-5. Basic architecture for process pools
The initial section is again similar to the earlier programs, except that we check the command line to see how large a process pool to create:
/* server3.c *
/
#include <stdio.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(int argc, char *argv[])
{
First, we declare the variables that we will need.
struct sockaddr_in sAddr;
int listensock;
int newsock;
char buffer[25];
int result;
int nread;
int pid;
int nchildren = 1;
int x;
int val;
Then, we check the command line to see how many processes will be in our process pool. If nothing is specified, then we create only one listening process.
if (argc > 1) {
nchildren = atoi(argv[1]);
}
We create the socket that will listen for incoming connections.
listensock = socket(AF_INET, SOCK_STREAM,
IPPROTO_TCP);
Again, we set the SO_REUSEADDR option.
val = 1;
result = setsockopt(listensock,
SOL_SOCKET, SO_REUSEADDR, &val, sizeof
(val));
if (result < 0) {
perror("server3");
return 0;
}
Next, we bind it to a local port and all addresses associated with the machine.
sAddr.sin_family = AF_INET;
sAddr.sin_port = htons(1972);
sAddr.sin_addr.s_addr = INADDR_ANY;
result = bind(listensock, (struct sockaddr
*) &sAddr, sizeof(sAddr));
if (result < 0) {
perror("server3");
return 0;
}
Now we put it into listening mode.
result = listen(listensock, 5);
if (result < 0) {
perror("server3");
return 0;
}
We create the specified number of child processes for the process pool using the fork() system call:
for (x = 0; x < nchildren; x++) {
if ((pid = fork()) == 0) {
Each child process calls accept on the same listening socket. When a client connects, the system will choose the next child in line to notify:
while (1) {
newsock = accept(listensock, NULL,NULL);
Once a client connects, we read characters it sends, echo them to the screen and client, and close the connection:
printf("client connected to child
process %i.\n", getpid());
nread = recv(newsock, buffer, 25, 0);
buffer[nread] = '\0';
printf("%s\n", buffer);
send(newsock, buffer, nread, 0);
close(newsock);
printf( "client disconnected from
child process %i.\n", getpid());
}
}
}
This tells the parent process to wait until all of the children have been com pleted, before continuing. Of course, none of the children in this example will ever be completed:
wait(NULL)
;
}
Figure 5-6 shows a sample of the output obtained on executing the program. The client was run with five child processes.
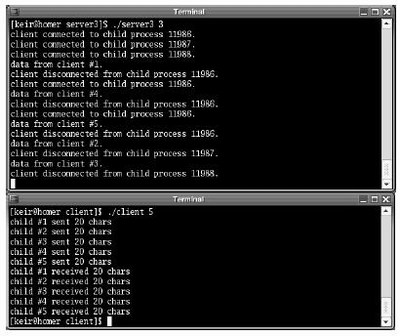
Figure 5-6. Output from a preforking server
Notice that the processes are used in the order in which they called accept() . Since we have more clients than processes in the process pool, earlier processes are reused for new clients once they become free.
More recently, using threads has become the preferred method for handling multiple clients. Threads are lightweight processes that share the main memory space of the parent process. Because of this, they use fewer resources than a multiprocess application, and they enjoy a faster context-switch time. However, multithreaded applications are not as stable as multiprocess applications. Because of the shared memory if, say, a buffer overrun occurs in one thread, it can impact other threads. In this way, one bad thread can bring down the entire server program. This isn’t the case with multiprocess applications, where the memory in each process is protected from alteration from another process by the operating system. This keeps an errant process from corrupting the memory of another process.
Before moving on, let’s talk a little more about shared memory in multi-threaded server applications. If not handled correctly, the shared memory can be a double-edged sword. Remember that global variables will be shared by all threads. This means that to keep client-specific information, you must take advantage of the thread-local storage mechanisms provided by your thread library. These allow you to create “thread-global” values that aren’t shared between threads.
If you do have global variables that need to be shared between threads, it is very important to use the synchronization objects like mutexes to control access to them. Without synchronization objects, you can run into very strange behaviors and even unexplained program crashes. Most often this occurs when one thread is writing to a variable when another is reading or writing to the same variable. This situation can cause memory corruption, and it may not show itself immediately but will eventually cause problems. Multithreaded applications are hard enough to debug, so synchronize access to all global variables and structures.
The version of POSIX threads distributed with most flavors of Linux was developed by Xavier Leroy. His website, http://pauillac.inria.fr/~xleroy/ linuxthreads , has more information. In addition, there are many other resources on the Internet for references on pthread programming. You can find a new thread library based on GNU’s pth library at http://oss.software.ibm.com/ developerworks/opensource/pthreads .
As with the multiprocess strategy, using one thread per client is the simplest multithreaded server architecture. Again, the client logic in each thread does not have to stop to service other connected clients, but is free to focus on one client. One caveat, though, is that the maximum number of threads allowed on a system is far less than the maximum number of processes. With a server that needs to maintain a large number of persistent connections, you may want to consider using one of the other architectures presented in this chapter.
A Multithreaded ServerNote the multithreaded server’s similarity to the multiprocess model. In the following program ( server4.c ), the parent server process waits for client connections. When a connection occurs, the server creates a new thread and passes the new socket descriptor to it. The new thread then reads data from the client and echoes it back. Finally, the connection is closed, and the thread exits. Meanwhile, the parent process loops and waits for another connection. Figure 5-7 shows the basic architecture for a multithreaded server.
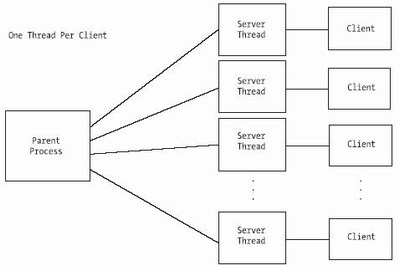
Figure 5-7. Basic architecture for a multithreaded server
Again, the initial section of the code is similar to that in the previous programs:
/* server4.c *
/
#include <stdio.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>
void* thread_proc(void *arg);
int main(int argc, char *argv[])
{
First, we declare the variables that we will need.
struct sockaddr_in sAddr;
int listensock;
int newsock;
int result;
pthread_t thread_id;
int val;
Next, we create the socket that will listen for incoming connections.
listensock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
Now we set the SO_REUSEADDR socket option.
val = 1;
result = setsockopt(listensock, SOL_SOCKET, SO_REUSEADDR, &val, sizeof(val));
if (result < 0) {
perror("server4");
return 0;
}
Then, we bind it to a local port and all addresses associated with the machine.
sAddr.sin_family = AF_INET;
sAddr.sin_port = htons(1972);
sAddr.sin_addr.s_addr = INADDR_ANY;
result = bind(listensock, (struct sockaddr *) &sAddr, sizeof(sAddr));
if (result < 0) {
perror("server4");
return 0;
}
We then put the socket into listening mode.
result = listen(listensock, 5);
if (result < 0) {
perror("server4");
return 0;
}
As in server2.c , we call accept() and let it block until a client tries to connect:
while (1) {
newsock = accept(listensock, NULL,NULL);
Once a client connects, a new thread is started. The descriptor for the new client socket is passed to the thread function. Since the descriptor is passed to the function instead of being copied, there will be no need for the parent thread to close the descriptor:
result = pthread_create(&thread_id, NULL, thread_proc, (void *) newsock);
if (result != 0) {
printf("Could not create thread.\n");
}
Since the parent thread will be in a continuous loop, there will be no need to ever join one of the child threads. Therefore, we call pthread_detach()to keep zombies from occurring. A zombie is a process (or thread, in this case) that has returned and is waiting for its parent to check its return value. The system will keep the zombies around until the return value is checked, so they just take up resources. In our example, we aren’t interested in the thread’s return value, so we tell the system by calling pthread_detach() . Then, we call sched_yield() to give the new thread a chance to start execution by giving up the remainder of the parent’s allotted time-slice.
pthread_detach(thread_id);
sched_yield();
}
}
void* thread_proc(void *arg)
{
int sock;
char buffer[25];
int nread;
In our thread function, we cast the passed argument back to a socket descriptor. Notice that we don’t close the listening socket as we did in server2.c. In a threaded server, the descriptors aren’t copied to the child process, so we don’t have an extra listening socket descriptor in the child. Next is the familiar routine: read characters, echo them to the screen and client, and close the connection.
printf("child thread %i with pid %i created.\n", pthread_self(),
getpid());
sock = (int) arg;
nread = recv(sock, buffer, 25, 0);
buffer[nread] = '\0';
printf("%s\n", buffer);
send(sock, buffer, nread, 0);
close(sock);
printf("child thread %i with pid %i finished.\n", pthread_self(),
getpid());
}
The server can be compiled with the following command. Notice that we are linking with the pthread library. This is the library that gives us the threading capabilities.
gcc -o server4 -lpthread server4.c
Figure 5-8 shows a sample of the output obtained on executing the program. The client was run with five child processes.

Figure 5-8. Output from a multithreaded server
Notice that, for a short time, all of the clients are connected at the same time.
Thread pools operate in a very similar manner to process pools. Our strategy is to create a certain number of threads when the application initializes. We then have a pool of threads to handle incoming client connections, and we avoid the costs associated with waiting to create a thread when the request is made. In addition, with shared memory, it is much easier to implement dynamic thread pools in which we can resize our thread pool at runtime depending on the load requirements.
On the downside, if one thread crashes, it can bring down the entire server application. This is due to the fact that all of the threads, including the main appli cation process, use the same memory space and resources (for example, file descriptors). So, for example, if one of the threads encounters a buffer overrun problem, it can corrupt memory being used by another thread. This is not the case with multiple processes, because the operating system prevents one process from writing over the memory in another process. Great care must be taken when designing a multithreaded server to prevent an errant thread from affecting the others.
Figure 5-9. shows the basic architecture for a prethreaded server application.
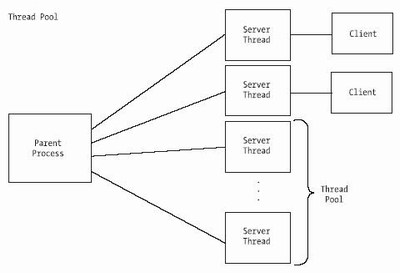
Figure 5-9. Basic architecture for a prethreaded server application
In the following program ( server5.c ), the number of threads in the pool is passed in on the command line. The parent process then uses a loop to spawn the requested number of threads, passing the descriptor of the listening socket. It then calls pthread_join()to keep it from returning before any of its threads. If we didn’t insert this call, the parent process would end immediately and cause all its threads to return. Each thread then calls accept on the same listening socket and waits for a client connection. When a connection is made, the operating system chooses one of the threads to signal using a “first in, first out” methodology. This thread receives the data from the client and echoes it back. Finally, the connection is closed, and the thread calls accept() again to wait for another client.
These lines are very similar to the section in the program server3.c :
/* server5.c *
/
#include <stdio.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>
void* thread_proc(void *arg);
int main(int argc, char *argv[])
{
First, we declare the variables that we will need.
struct sockaddr_in sAddr;
int listensock;
int result;
int nchildren = 1;
pthread_t thread_id;
int x;
int val;
We check the command line to see how many threads should be in our thread pool. If none is specified, then we will create a single thread.
if (argc > 1) {
nchildren = atoi(argv[1]);
}
Next, we create the socket that will listen for incoming connections.
listensock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
Then, we set the SO_REUSEADDR option.
val = 1;
result = setsockopt(listensock, SOL_SOCKET, SO_REUSEADDR, &val, sizeof(val));
if (result < 0) {
perror("server5");
return 0;
}
We bind it to a local port and to all addresses associated with the machine.
sAddr.sin_family = AF_INET;
sAddr.sin_port = htons(1972);
sAddr.sin_addr.s_addr = INADDR_ANY;
result = bind(listensock, (struct sockaddr *) &sAddr, sizeof(sAddr));
if (result < 0) {
perror("server5");
return 0;
}
We now put it into listening mode.
result = listen(listensock, 5);
if (result < 0) {
perror("server5");
return 0;
}
Afterward, we create our pool of threads. Notice that we pass the descriptor for the listening socket instead of the client:
for (x = 0; x < nchildren; x++) {
result = pthread_create(&thread_id, NULL, thread_proc,
(void *) listensock);
if (result != 0) {
printf("Could not create thread.\n");
}
sched_yield();
}
Here, we call pthread_join() . This has the same effect that calling wait() did in server3.c . It keeps the parent thread from continuing until the child threads are finished:
pthread_join (thread_id, NULL);
}
void* thread_proc(void *arg)
{
int listensock, sock;
char buffer[25];
int nread;
listensock = (int) arg;
while (1) {
Each thread calls accept() on the same listening socket descriptor. Just as in server3.c , when a client connects, the kernel will choose a thread in which accept() returns:
sock = accept(listensock, NULL, NULL);
Once accept() returns, we read the data from the client and echo it back. Then we close the connection.
printf("client connected to child thread %i with pid %i.\n",
pthread_self(), getpid());
nread = recv(sock, buffer, 25, 0);
buffer[nread] = '\0';
printf("%s\n", buffer);
send(sock, buffer, nread, 0);
close(sock);
printf("client disconnected from child thread %i with pid %i.\n",
pthread_self(), getpid());
}
}
The server can be compiled with the following command:
gcc -o server5 -lpthread server5.c
This will run the server with five threads in the thread pool:
./server5 5
Figure 5-10 shows a sample of the output obtained on executing the program. The client was run with five child processes.
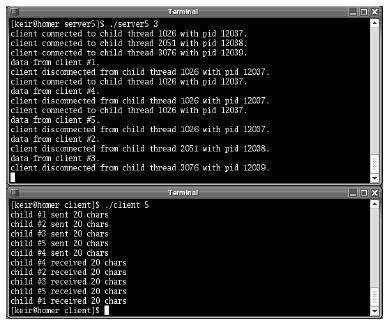
Figure 5-10. Output from a prethreaded server
Notice that the threads are used in the order in which they called accept() . Since we have more clients than threads in the thread pool, earlier threads are reused for new clients once they become free.
Starting with version 2 of the Apache Web Server, the Apache Project (http://httpd.apache.org) implemented a hybrid of the preforking and prethreading strategies. What the group hoped to achieve was the speed of prethreading combined with the stability of preforking.
As mentioned earlier in the chapter, a multiprocess server doesn’t crash when one of the child processes crashes, but it suffers from slower context switching. Multithreaded servers, on the other hand, do crash when one of the child threads crashes, but have faster context switching. The developers at Apache have combined the two approaches to increase the benefits while mini mizing the drawbacks. Figure 5-11 shows this hybrid architecture.
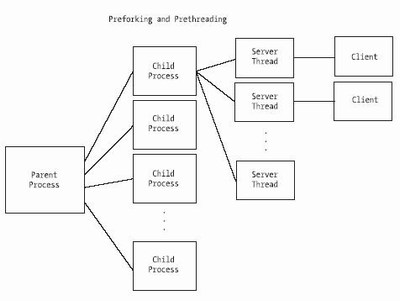
Figure 5-11. Combining preforking with prethreading
The way it works is by preforking a number of server processes. However, these processes do not handle client connections. Instead, each child process spawns a finite number of threads. The threads handle client connections. Thus, when dealing with multiple clients, the server enjoys fast context-switching. As for crashes, if a thread crashes, it takes out only other threads from the same child process instead of the whole web server. Apache also provides a setting that sets a number of requests that a process handles before it is terminated and a new process (with child threads) is created. This ensures that resource leaks in any one process will be cleaned up periodically.
TIP Don’t forget about multiplexing. Multiplexing can be added to a multiprocess or multithreaded server to increase scalability. Using this strategy, you can handle very large numbers of simultaneous users because each process or thread can handle more than one client. You can even combine all three and have a multiprocess, multithreaded server with multiplexing.
Which Method Should You Choose?
Your choice of method should be made based on the requirements of the server you want to develop and the available resources in the environment in which the server will run. Multiplexing is ideal for a low-volume server to which clients will not stay connected for a long period of time. The danger with a multiplexing server is that any one client might monopolize the server’s time and cause it to stop responding to the other connected clients. In addition, a multiplexing server cannot take advantage of symmetric multiprocessing (SMP) capabilities. The reason is that a multiplexing server consists of a single process and, since a process cannot be spread across multiple CPUs, the server will only ever use one CPU.
For ease of implementation, you can’t beat one process or thread per client. Processes win in stability, while threads win in context-switch time, resource use, and shared memory. Here, you must determine whether you need to coordinate the actions of clients. In a web server, for example, the clients are autonomous. So, the lack of shared memory isn’t really a concern. On the other hand, if you’re designing a multiuser enterprise application, then coordinating clients can be very important, and shared memory is essential. Of course, while using process pools can help with the context switching, when a client connects, it will still suffer from the lack of simple shared memory.
Table 5-1 summarizes the pros and cons of each method.
In practice, the data transmitted between the client and the server is much larger than that dealt with in the examples earlier in this chapter. Such large amounts of data generate a few issues. First, large amounts of data will be broken up in the underlying transport layer. IP has a maximum packet size of 65,536 bytes, but even smaller amounts of data may be broken up depending on buffer availability. This means that when you call recv() , for example, it may not return all of the data the first time, and subsequent calls may be required. Second, while you are sending or receiving large amounts of data, you require your user interface to be responsive. In this section, we will address these issues.
Nonblocking Sockets
The first step to carry out large-sized data transfers is to create nonblocking sockets. By default, whenever we create a socket, it will be a blocking socket. This means that if we call recv() and no data is available, our program will be put to sleep until some data arrives. Calling send()will put our program to sleep if there is not enough outgoing buffer space available to hold all of the data we want to send. Both conditions will cause our application to stop responding to a user.
Table 5-1. Method Pros and Cons
|
Method |
Multiplexing |
Forking |
Threading |
Preforking |
Pre threading |
Preforking plus pre threading |
|
Code Complexity |
Can be very complex and difficult to follow |
Simple |
Simple |
Can be complex if using a dynamic pool and shared memory |
Only complex if using a dynamic pool |
Complex |
|
Shared Memory |
Yes |
Only through shnget() |
Yes |
Only through shnget() |
Yes |
Yes but only within each process |
|
Number of Connections |
Small |
Large |
Large, but not as large as forking |
Depends on the size of the process pool |
Depends on the size of the thread pool |
Depends on pool sizes |
|
Frequency of New Connections |
Can handle new con nections quickly |
Time is required for a new process to start |
Time is required for a new thread to start |
Can handle new con nections quickly if the process pool is large enough |
Can handle new con nections quickly if the thread pool is large enough |
Can handle new con nections quickly if pools are large enough. |
|
Length of Connections |
Good for long or short con nections |
Better for longer con nections. Reduces start penalty. |
Better for longer con nections. Reduces thread start penalty. |
Good for long or short con nections |
Good for long or short con nections |
Good for long or short con nections |
|
Stability |
One client can crash the server |
One client can crash the server |
One client can crash the server |
One client cannot crash the server |
One client can crash the server |
One client will crash only its parent process not the whole server |
|
Context Switching |
N/A |
Not as fast as threads |
Fast |
Not as fast as threads |
Fast |
Fast |
|
Resource Use |
Low |
High |
Medium |
High |
Medium |
Similar to threading but depends on how much pre forking is done |
|
SMP Aware |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
Creating a nonblocking socket involves two steps. First, we create the socket as we would usually, using the socket function. Then, we use the following call to ioctl() :
unsigned long nonblock = 1
;
ioctl(sock, FIONBIO, &nonblock);
With a nonblocking socket, when we call recv() and no data is available, it will return immediately with EWOULDBLOCK . If data is available, it will read what it can and then return, telling us how much data was read. Likewise with send() , if there is no room in the outgoing buffer, then it will return immediately with EWOULDBLOCK . Otherwise, it will send as much of our outgoing data as it can before returning the number of bytes sent. Keep in mind that this may be less than the total number of bytes we told it to send, so we may need to call send again.
The select() call from the section on multiplexing is the second step to carry out large-sized data transfers. As mentioned earlier, we use select() to tell us when a socket is ready for reading or writing. In addition, we can specify a time-out, so that in case a socket is not ready for reading or writing within a specified time period, select() will return control to our program. This allows us to be responsive to a user’s commands while still polling the socket for activity.
Putting It All TogetherCombining nonblocking sockets with select() will allow us to send and receive large amounts of data while keeping our application responsive to the user, but we still need to deal with the data itself. Sending large amounts of data is rela tively easy because we know how much we need to send. Receiving data, on the other hand, can be a little harder unless we know how much data to expect. Because of this, we will need to build into our communications protocol either a method to tell the receiving program how much data to expect or a fixed data segment size.
Communicating the expected size of the data to the receiver is fairly simple. In fact, this strategy is used by HTTP, for example. The sender calculates the size of the data to send and then transmits that size to the receiver. The receiver then knows exactly how much data to receive.
Another option is to use a fixed-sized segment. In this way, we will always send the same amount of data in each segment sent to the receiver. Because of this, the sender may need to break up data into multiple segments or fill undersized segments. Therefore, care must be taken in determining the segment size. If our segment size is too large, then it will be broken up in the transport and will be inefficient. If it is too small, then we will incur a lot of underlying packet overhead by sending undersized packets. The extra work on the sending side pays off on the receiving side, however, because the receiving is greatly simplified.
Since the receiver is always receiving the same amount of data in each segment, buffer overruns are easily preventable. Using fixed sizes can be a little more complex on the sending side, but simpler on the receiving side.
Finally, here is some code that demonstrates sending data using nonblocking sockets and select() . The strategy for receiving data is very similar.
int mysend(int sock, const char *buffer, long buffsize) {
NOTEThis code does not deal with the Big Endian/Little Endian issue. It sends a buffer of bytes in the order provided. If you will be dealing with clients and servers that use differing byte orders, then you will need to take care in how the data is formatted before sending with this function.
First, we declare some variables that we’ll need.
fd_set fset ; struct timeval tv; int sockStatus; int bytesSent; char *pos; char *end; unsigned long blockMode;
Then, we set the socket to nonblocking. This is necessary for our send but can be removed if we are already using nonblocking sockets.
/* set socket to non-blocking */ blockMode = 1; ioctl(sock, FIONBIO, &blockMode);
Now we set up a variable to keep our place in the outgoing buffer and a vari able to point to the end of the buffer.
pos = (char *) buffer ; end = (char *) buffer + buffsize;
Next, we loop until we get to the end of the outgoing buffer.
while (pos < end) {
We send some data. If send() returns a negative number, then an error has occurred. Note that 0 is a valid number. Also, we want to ignore an error of EAGAIN , which signifies that the outgoing buffer is full. Our call to select() will tell us when there is room again in the buffer.
bytesSent = send(sock, pos, end - pos, 0); if (bytesSent < 0) { if (bytesSent == EAGAIN) { bytesSent = 0; } else { return 0; } }
We update our position in the outgoing buffer.
pos += bytesSent;
If we are already to the end of the buffer, then we want to break out of the while loop. There is no need to wait in the select() because we are already done.
if (pos >= end) { break; }
Next, we get our watch list ready for select() . We also specify a timeout of 5 seconds. In this example, we treat a timeout as a failure, but you could do some processing and continue to try and send. It is important to use select() here because if the outgoing buffer is full, then we end up with a tight busy-wait loop that can consume far too many CPU cycles. Instead, we allow our process to sleep until buffer space is available or too much time has lapsed without space becoming available.
FD_ZERO(&fset); FD_SET(sock, &fset); tv.tv_sec = 5; tv.tv_usec = 0; sockStatus = select(sock + 1, NULL, &fset, &fset, &tv); if (sockStatus <= 0) {
return 0; } }
return 1; }
SummaryIn this chapter, we looked at the different ways to handle multiple, simultaneous clients. First, we examined how to handle multiple clients in a single server process by using multiplexing. Then, we moved on to multiprocessing servers and the single process per client versus a process pool. Next, we introduced multi threaded servers. Much like multiprocess servers, multithreaded servers can be either a one-thread-per-client or a thread-pooled architecture. Afterward, we looked at an interesting approach used by the Apache Web Server version 2, in which multiprocessing is combined with multiple threads. We closed the chapter by covering how to handle sending and receiving large amounts of data by using nonblocking sockets and the select() system call.
In this chapter, we looked at the different ways to handle multiple, simultaneous clients. First, we examined how to handle multiple clients in a single server process by using multiplexing. Then, we moved on to multiprocessing servers and the single process per client versus a process pool. Next, we introduced multithreaded servers. Much like multiprocess servers, multithreaded servers can be either a one-thread-per-client or a thread-pooled architecture. Afterward, we looked at an interesting approach used by the Apache Web Server version 2, in which multiprocessing is combined with multiple threads. We closed the chapter by covering how to handle sending and receiving large amounts of data by using nonblocking sockets and theselect()system call.In the next chapter, we’ll examine what’s involved in implementing a custom protocol.