


Next: Design and Implementation of
Up: Research Thrusts for Reverse
Previous: Research Thrusts for Reverse
As presented in Section 1, PRC is an extension of
TiPRC which generates no entropy in the form of information
loss. Recall, that TiPRC generates entropy in the form of control
information (i.e., records which branch was taken or how many times
through a loop plus incrementally state-saves any destructive
assignments). This control information was stored in a bit field. PRC
has no such bit field. PRC is able to execute forward or backward
based solely on the current state of the system.
To support PRC in general, a program cannot produce any information
loss. This means PRC should allow arbitrarily-long reversible
computations through simulated time consuming only a constant
amount of memory. This is the fundamental difference between PRC and
TiPRC. TiPRC creates garbage in the form of control bits, and thus
reverse execution can only be supported over a small range of
simulated time. Once the garbage bits are collected, TiPRC cannot
reverse beyond that point in the computation.
To illustrate how PRC would work in practice, consider the following
timing diagram of a network model from [76] (see
Figure 2). Suppose we have three LPs. The first two are
Node LPs that are able to send and receive packets to each other and
manage a finite amount of buffer space. Connecting these two Node LPs
is a Link LP which is responsible for storing the current usage and
availability on this link. Assume that LP 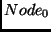 is at virtual time
is at virtual time
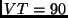 , LP
, LP 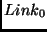 is at
is at  and LP
and LP 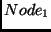 is at . Now
consider the following exchange of events:
is at . Now
consider the following exchange of events:
- LP , currently at , requests
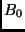 units of
bandwidth at virtual time,
units of
bandwidth at virtual time, 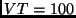 to LP .
to LP .
- LP processes the request at and responds to
LP with
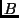 units of bandwidth and decrements its available
bandwidth by units at
units of bandwidth and decrements its available
bandwidth by units at 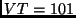 .
.
- LP requests
 units of bandwidth at to
LP .
units of bandwidth at to
LP .
In a classic optimistic synchronization scheme, LP would
rollback to because the request message from LP is in
the past and thus an error with respect to event causality. By rolling
back, would have scheduled an ``anti-message'' for LP .
However, under PRC, rollback can be realized by running the simulation
backwards. This is effectively accomplished by the following series of
``reverse'' events:
- LP detects the out-of-order event execution and
issues a reverse event to LP at . The reverse event here is used to find the leading edge of the incorrect
event computation path. 's direction state is changed to reverse causing it to only process reverse events. Since it has no
other reverse events to process, it waits until it receives
one. Observe that the arriving forward event at
 is
ignored. When operating in reverse, an LP processes events in largest
or highest timestamp order.
is
ignored. When operating in reverse, an LP processes events in largest
or highest timestamp order.
- Assume the forward event at has been processed. Upon
receiving the reverse event, LP immediately ``undoes''
the event at using the event data and it's current state as
input. As part of reverse processing this event, it schedules a
``reverse'' event at to LP .
- LP receives the reverse event at executes
backward to using the event and it current state as input. As
part of reverse event processing, it schedules a reverse event to LP
at . Because its local clock is less than the
rollback time of , switches back to forward execution
and processes the event at sent by LP .
- reverse executes the reverse event at .
It then observes its current local virtual time is , which is
equal to the rollback time and so it to switches back to forward
execution of events and re-processes the event at .
The above scenario is kept simple to illustrate how PRC would work.
This example motivates the research thrust areas which are discussed
below.
Next: Design and Implementation of
Up: Research Thrusts for Reverse
Previous: Research Thrusts for Reverse
Christopher D. Carothers
2002-03-07