Agents and the Semantic Web
James Hendler
Department of Computer Science
University of Maryland
College Park, MD 20742
Hendler@cs.umd.edu
At a colloquium I attended recently, a speaker referred to a "science fiction vision" that was comprised of sets of agents running around the web being able to perform complex actions for their users. His argument was that we were far from the day that this would be real, and that the infrastructure was not in place to make this happen. While I agree with his latter assessment, I believe the former is far too pessimistic. Furthermore, a crucial component of this infrastructure, a "standardized" web ontology language, is now starting to emerge. In this paper, I provide a few pointers to this emerging area, and then go on to show how the ontology languages of the semantic web can lead directly to more powerful agent-based approaches to using services offered on the web -- that is, to the realization of my colleague’s "science fiction" vision.
Ontologies on the Semantic Web
There are a number of vocabulary terms we use, and sometimes abuse, in the AI community. These terms become even more confusing when we interact with other communities, such as web toolkit developers, who abuse some of the very same terms. One example of such a term is ontology, which was traditionally defined as 'the science or study of being' (Oxford English Dictionary). In AI, usually attributed to (Gruber, 1993) the notion of ontology is, essentially, "the specification of a conceptualization" -- that is, defined terms and relationships between them, usually in some formal (preferably machine-readable) manner. Even more complicated is the relationship between ontologies and logics — some people treat ontology as a subset of logic, some treat logic as a subset of ontological reasoning, and other uses have been bandied about.
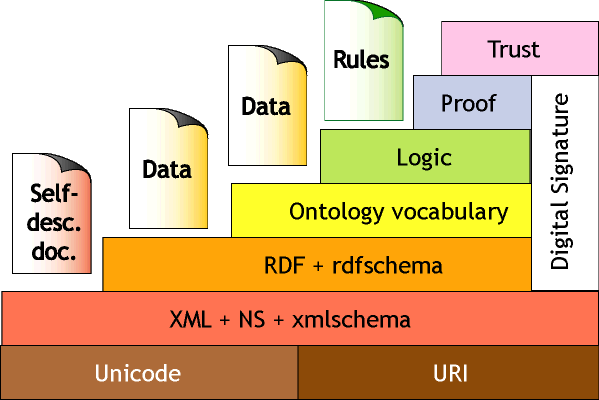
In this paper, I will use these word s as it is currently being used in "semantic web" circles --that, is, as a set of knowledge terms, including the vocabulary, the semantic interconnections and some simple rules of inference and logic, for some particular topic. For example the ontology of cooking and cookbooks includes ingredients, how to stir and combine them, the difference between simmering and deep-frying, the expectation that the products will be eaten or drunk, that oil is for cooking in or consuming and not for lubrication, and so forth. More complex logics and inference systems are generally considered as separate from the ontology per se. Figure 1, from a talk given by Tim Berners-Lee at the recent XML-2000 Conference (Washington DC, Dec, 2000), shows the proposed layers of the semantic web, with higher level languages using the syntax (and semantics) of lower levels. This paper focuses primarily on the ontology language level, and the sort of agent-based computing that they enable. Higher levels (with complex logics and the exchange of proofs to establish trust relationships) will enable even more interesting functionality, but are left for discussion in later papers.
Figure 1: The Semantic Web "layer cake" as presented by Tim Berners-Lee.
Recently, a number of research groups have been developing languages in which to express ontological expressions on the web (see
http://www.daml.org/links for a list of these and related efforts). In an effort to bring these together, and to try to arrive at a de facto web standard, a number of researchers, supported by the US Defense Advanced Research Projects Agency (DARPA) released a draft language known as the DARPA Agent Markup Language (DAML). Since then, an ad hoc group of researchers has formed the "Joint US/EU committee on Agent Markup Languages" and released a new version of the language called DAML+OIL. This language is based on the Resource Description Framework (RDF, see http://www.w3.org/rdf) and discussion of its features is conducted on an open mailing list (archived at http://lists.w3.org/Archives/Public/www-rdf-logic/). Details of the language and a repository of numerous ontologies and annotated web pages can be found on http://www.daml.org/.In this paper, I will not describe the DAML language effort or other languages aimed at enabling semantics on the web. Rather, I want to look at some potential applications of these web semantics and consider some challenges we as a research community should be attacking. In particular, I want to look at how information agents and ontologies can together provide breakthrough technologies for web applications.
Semantic Web Ontologies
The Semantic Web, as I envision it evolving, will not be primarily comprised of nice neat ontologies that have been carefully constructed by expert artificial intelligence researchers. Rather, I envision a complex web of semantics ruled by the same sort of anarchy that currently rules the rest of the web. Rather than a few large, complex, consistent ontologies, shared by great numbers of users, I envision a great number of small ontological components largely created of pointers to each other and developed by web users in much the same way that web content is currently created.
I predict that in the next few years virtually every company, university, government agency or ad hoc interest group will want their web resources linked to ontological content –because of the many powerful tools that will be available for using it. Information will be exchanged between applications, allowing computer programs to collect and process web content, and to exchange information freely with each other. On top of this infrastructure, agent-based computing will become much more practical, in fact distributed computer programs interacting with non-local web-based resources may eventually become the dominant way in which computers interact with humans and each other, and will be a primary means of computation in the not-so-distant future.
However, for this vision to become a reality, a phenomenon similar to the early days of the web must occur. Web users will not markup their web pages unless they perceive a value to doing so, and tools to demonstrate this value will not be developed unless web resources are marked up. To help in solving this chicken and egg problem, DARPA is now funding a set of researchers both to develop freely available tools, and to provide significant content for these tools to manipulate – thus demonstrating to the government and other parts of society that the semantic web can be a reality, not just a vision. However, we still need more – without some killer applications showing the great power of web semantics, it will still be a long row to hoe. While I don’t claim to have all the answers, perhaps some of the ideas in the remainder of this paper will inspire the creation of some exciting web-agent applications.
I will develop this vision a step at a time – describing the creation of pages with ontological information, the definition of services in a machine-readable form, and the use of logics and agents that traverse such a web providing a number of new capabilities.
Markup For Free
A crucial aspect of creating the semantic web is to make it possible for a number of different users to create the machine-readable web content without being logic experts. In fact, ideally most of the users shouldn’t even need to know that web semantics exists. Lowering the cost of markup isn’t enough – for many users it needs to be free. That is, semantic markup should be a by-product of normal computer use. Much like current web content, a small number of tool creators and web ontology designers will need to know the details, but most users will not even know ontologies exist.
As an example, consider any of the well-known products for creating on-line slide shows. Several of these products contain libraries of clippings that can be inserted into the presentations. These clippings can be marked with pointers to ontologies by the developers of the software, and the saving of the products on the web (Save as HTML…), could include the linking of these saved products to the ontologies they’re marked from. Thus a presentation that had pictures of, for example, a cow and a donkey, would be linked to barnyard animals, mammals, animals, etc. While this would not guarantee appropriate semantics (the cow might be the mascot of some school or the donkey the icon of some political party), retrieval engines would be able to use the markups as clues to what are in the presentations and how they may be linked to other ones. The user simply creates a slide show as is done today, but the search tools do a better job of finding it based on content.
An alternative example would be a markup tool driven from one or more ontologies. For example, consider a homepage-creation tool that is driven by representing hierarchical class relations as menus. Properties of the classes could be tied to various types of forms, and these made available via simple web forms. A user could thus choose from a menu to add information about a person, and thence choose a relative (vs. friend, professional acquaintance, etc.) and thence a daughter. The system could then use the semantics to retrieve the properties of daughters specified in the ontology/ies and to display them to the user as a form to be filled out by filling in strings (like name), numbers (age); or to browse for related links (homepage), on-line images (photo-of), etc. The system would then lay these out using appropriate web tools, while also recording the relevant instance information.
Since the tool could be driven from any ontology, a library of terms could be created (and mixed) in any number of different ways. Thus, a single easy-to-use tool would allow the creation of home pages (using ontologies on people, hobbies, etc.), professional pages (using ontologies relating to specific occupations or industries), agency-specific pages (using ontologies relative to specific functions), etc. In an easy, interactive way a user would be assisted in creating a page and get the markup created for free. Notice, also, that mixtures of the various ontologies and forms could be easily created, thus helping to create the semantic web of pages linking to many different ontologies, as mentioned earlier.
Incremental Ontology Creation
Not only can pages be created with links to numerous ontologies, but also the ontologies themselves can include links between them to reuse (or change) terms. The notion of creating large ontologies by the combination of components is not unique to the semantic web vision (c.f. Clark and Porter, 1997). However, the ability to link and browse ontological relations enabled by the web’s use of semantics will be a powerful tool for those users who do know what ontologies are and why they should be used.
How will this work? Consider Mary, the web master for a new business-to-consumer web site for an online pet shop. Browsing through a web ontology repository (such as the one currently hosted at http://www.daml.org/ontologies/), she finds that there are a lot of interesting ontologies available. Selecting one of these, a product ontology, Mary uses a browser to choose the various classes and relations that she wants to include in her own ontology. Several of these may be need to be further constrained based on properties of her particular business. For example, Mary must define some of these properties for the various animals she will sell, and so on.
Searching further in the ontology repositories, she finds that there is a biological taxonomy that contains many classes such as feline, canine, mammal, animal, etc. and that these contain several properties relevant to her business, so she provides links to these. She adds a new descriptor field to animal called "product-shipping-type" and sets it to default to the value "alive" (not a standard property or default in the product ontology she chose to extend). Finally, she notices that although the biological ontology contained a number of kinds of felines, it didn’t use the categories she wanted (popular pets, exotic pets, etc.) She adds these classes as subclasses of the ones in the parent ontology and defines their properties. Saving this ontology on her web site, she is now able to use other ontology-based tools to help organize and manage her web site. Mary is motivated to add the semantics to her site both by these tools, and the other powerful browsing and search tools enabled by the semantics.
Following this, the many ontology-based search and browsing tools on the web, when pointed at her pages, are able to use this information to help distinguish her site from the many other (non-ontology based) sites being used by her competitors. This makes it easy for her to extend her site to use various B2B e-commerce tools that can take advantage of web ontologies for automated business tools. In addition, she may choose to submit her ontology back into one of the repositories, so that others in her profession can find it and use it for their own sites. After all, the power of the ontologies is in the sharing, and the more people using common terms with her, the better.
Ontologies and Services
One of the most powerful uses of the web ontologies described heretofore, and a key enabler for agents on the web, is in the area of web services. Recently, numerous small businesses, particularly those in the area of supply-chain-management for B2B e-commerce, have been discussing the role of ontologies in managing the machine-to-machine interactions. In most cases, however, these approaches have assumed that the ontologies are primarily used by the constructors of computer programs to make sure that they agree on terms, types, constraints, etc. Thus, the agreement is recorded primarily off line, and used in web management applications. On the semantic web we will go much further than this, creating machine-readable ontologies used by "capable" agents to find these web services and automate their use.
A well-known problem with the web of today is the difficulty in finding the many web services currently available on line. For example, back when I first started writing this article, I wanted to send a web greeting card, but didn't know the name of one of the companies offering such a service. Using standard keyword based searches did not help me much. The query "Web Greeting Card" found many hits from people who are displaying particular greeting cards, or who have these three terms at various places on their pages . In fact, these three keywords given to several of the most common search engines did not turn up the most popular of the web greeting card service provider in their top 20 suggestions. (A search on "eCards" would indeed find this site, but I didn't happen to know this particularly ugly neologism.) As I edit this paper for final consistency, the search engines are now finding this page, but if I want something more complex -- for example, an anniversary card for my mother-in-law that plays Hava Nagila, I'm still pretty much out of luck. As the number of services grows, and the specificity of our needs increases, the ability of current search engines to find the most appropriate services is strained to the limit.
A number of efforts are currently underway to help improve this situation (c.f. UDDI, 2000; ebXML, 2000; eSpeak, 2000). These efforts focus on what one may call a "service advertisement." By creating a controlled vocabulary of service advertisements, search engines could find these web services. Thus, Mary’s Pet Site, as discussed above, might have an annotation that it provides a "Sell" service of object "Pet" and thus pet buyers would more easily be able to find it. Similarly, a web greeting card site could register as something like a "personal service, e-mail, communications" and a user could more easily get to it without knowing the term "ecard."
However, I argue that semantic web techniques can, and must, go much further. The first use of ontologies on the web for this purpose is pretty straightforward – by creating the service advertisements in an ontological language, tools could use the hierarchy (and property restrictions) to find matches via the class/subclass properties or other semantic links. For example, someone looking to buy roses might find florists (who sell flowers) even if there were no exact match that served the purpose. Using, for example, description logic (or other inferential means), the user could even find categorizations that weren’t explicit. So, for example, specifying a search for animals that were of "size = small" and "type = friendly," the user could end up finding the Pet Shop Mary is working for, which happens to specialize in hamsters and gerbils.
Futhermore, using a combination of web pointers, web markup, and ontology languages, we can do even better than just putting service advertisements into ontologies. Rather, using these techniques we can also include a machine-readable description of a service (as to how it runs) and some explicit logic describing the consequences of using the service. In fact, it is these latter two properties – a service description and a service logic – that would lead us to the integration of agents and ontologies in some exciting ways, as I will discuss in the next section.
Agents and Services
In an earlier article (Hendler, 1999), I described a vision of intelligent web agents using the analogy of travel agents – rather than doing everything for a user, the agents would find possible ways to meet user needs, and offer the user choices for their achievement. Much as a travel agent might give you a list of several flights you could take, or a choice of flying vs. taking a train, a web agent should offer a slate of possible ways to get you what you need on the web.
Consider the following example (a web-enabled method for saving the doomed crew of The Perfect Storm, Junger, 1997). In this story, now a major motion picture, a crew of fishermen is out at sea when weather conditions conspire to create a storm of epic proportions. For various reasons, the crew is unable to get a detailed weather map, and thus miss the fact that the storm is developing right in their way. Instead of avoiding it, they end up at its center with tragic results. How could web agents have helped?
As the Captain of the ship goes to call land, a wave hits and his cell-phone is swept overboard. Luckily, he is a savvy web user, and has brought his wireless web device with him as well.
Query Processed:
Figure 2: Results of processing agent-based query.
Checking the weather forecast from a standard weather site, he determines that a storm is coming, but he does not find enough detail for his planning needs. He goes to an agent-enabled geographical server site and invokes the query "Get me a satellite photo of this region of the Atlantic (and draws a box on an appropriate map)." The system comes back a little later with the message displayed in Figure 2. Options range from a picture available on the web (possibly out of date) to other services (that may need special resources) and even future options currently being announced. The captain now chooses an option depending on what resources he has available and what criterion he is willing to accept. Recognizing the gravity of his situation, he invokes the Coast Guard option, and an overflight is scheduled for his GPS location. Seeing the emerging weather, the Coast Guard arranges an emergency pickup at sea, and the sailors are able to go on to fish again some other day.
Using the tools of the semantic web, we can make this sort of thing routine and available to any user who needs to use a web service for any purpose by enabling expressive service capability advertisements to be made available to, and usable by, agents on the web. Figure 3 contains a graphical depiction of a complete instance of a potential a service class. Each service class has three properties: a pointer to the service advertisement as discussed above, a pointer to a service description, and a declarative service logic. I will discuss the service logic later, but first want to concentrate on service descriptions.
Consider visiting a current business-to-consumer (B2C) website such as any of the various book vendors on the web. When you are ready to order, you go to a web page and usually find some sort of form. Filling out the form, you click on a "submit" button and then are either taken to another form, or perhaps returned to the same form to provide missing information or fix an error. On hitting a new form the same may happen, until eventually all the information is provided and an order is completed. Most other web services have similar sorts of interactions, whether to buy an item, get directions to a location, find a particular image, etc.
The most common way of developing these systems is via the Common Gateway Interface (CGI), in which procedural code is written to invoke various functions of the web protocols. This code links the set of web pages to some sort of external resource. Thus, the invocation procedure is represented procedurally on the web, and an agent visiting the page cannot easily determine the set of information that must be provided or analyze other features of the code.
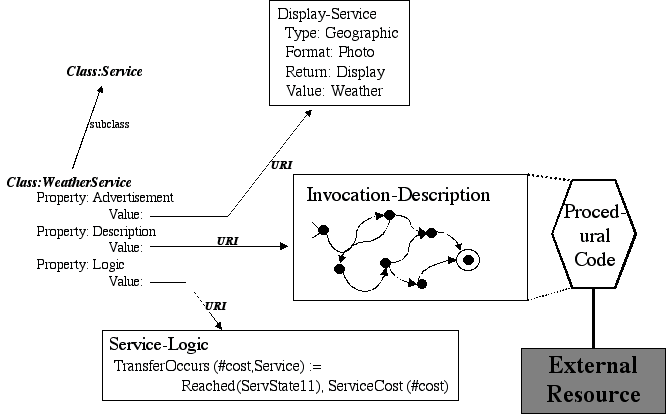
Figure 3 Complete Service Class on the Semantic Web
On the semantic web, I propose that it will be an easy matter to solve this using a declarative framework. While I believe that eventually one might wish to use some sort of web-enabled logic-programming language, one can get started in a much simpler way. In Figure 3, we represent the invocation of the procedural code via a simple finite state automaton. An ontology language such as DAML+OIL could be easily used to define an ontology, not of services, but of the terms needed to describe the invocation of services.
Using the example of a Finite State Machine, we can see what this ontology might contain. It would start with classes such as State and Link and have special subclasses such as StartState and EndState. Constraints and properties would be described to give links a head and tail, to give states a list of the links that lead out from them, and to give states a name, URI, and/or other identifying property. This would provide a "base" ontology which specific types of service providers could extend (much as Mary extended a biological ontology in the earlier example), and in which it would be easy for specialized ontologies to describe sets of terms for general use. (Thus, for example, a "standard web sale" could be defined in some service ontology as being comprised of a particular set of states and links. A service provider could then simply say that a particular part of a transaction was a "standard web sale" and via pointer following on the web, the necessary set of links and nodes could be found).
By creating such ontologies an exciting capability arises. Since these ontologies are web-enabled and declarative, agents coming to a page containing a service description could analyze the FSM found there and would be able to determine the particular information needs for invoking the service (and reaching an EndState). Thus an agent that had access to a set of information about a user could analyze the FSM and determine if that information would be sufficient for using this service. If not, the user could be informed as to what additional information would be or some other action could be taken.
While I’ve described primarily a finite state machine approach, there is no reason this couldn’t be done using any other declarative framework. More expressive logic languages or other declarative program frameworks would extend the capabilities of agents to analyze the information needs, resource requirements, processing burden, etc. of the services so described. Further, as these languages were linked to CGI scripts or other procedural techniques, procedural invocation could be done by the agents – letting them actually run the services (without user intervention) – thus allowing a very general form of agent interaction with off-web resources.
Service Logics
Going one step further, as well as defining languages that allow users to define "structural" ontologies, such as those discussed above, current efforts (including the DARPA DAML initiative) are also exploring the extension of such web ontologies to allow rules to be expressed within the languages. These efforts vary in the complexity of the rules allowed ranging from Description Logics (as in the DAML+OIL language mentioned earlier), to SHOE’s use of Horn-Clause-like rules (Heflin et al, 1998), all the way to both first- and higher- order logics in a number of exploratory efforts.
Whatever types of rules are being used, one place they can be effective is in connection with the service classes, as shown in figure 2. The service class contains, as well as the service advertisement and service description described previously, a pointer to a URI containing associated service logic. This logic can be used to express information that is beyond that found in the service description.
For example, returning to the agent replies shown in Figure 3, consider the case in which the service offers an up to date picture (to be taken tomorrow) at some particular cost. A rule such as
TransferOccurs(#cost,Service) := Reached(ServState11), ServiceCost(#cost)
might be used to represent the information that the actual transfer of funds will occur upon reaching a particular site in the service invocation (ServState71 in this case). This information would not be obvious from the state machine itself – but could be very useful in various sorts of e-commerce transactions. For example, on the current web there are often times when users leave without completing a particular CGI script, and cannot always know if a transaction has occurred or not. Using service logics, such things could be made explicit.
More interesting transactional logics could also be used. Figure 4, for example, shows a potential interaction between two web agents that can use proof checking to confirm transactions. An agent sends an annotated proof to another, where the annotations may be pointers to where on the web a particular fact could be found or pointers to an ontology where a particular rule resides. The agent receiving this proof can analyze it, check the pointers (or decide they are trusted by some previous agreements) and check that the ontology is one it can read and agree with. This allows the agent to recognize that a valid transaction has occurred and to allow the funds to be transferred.
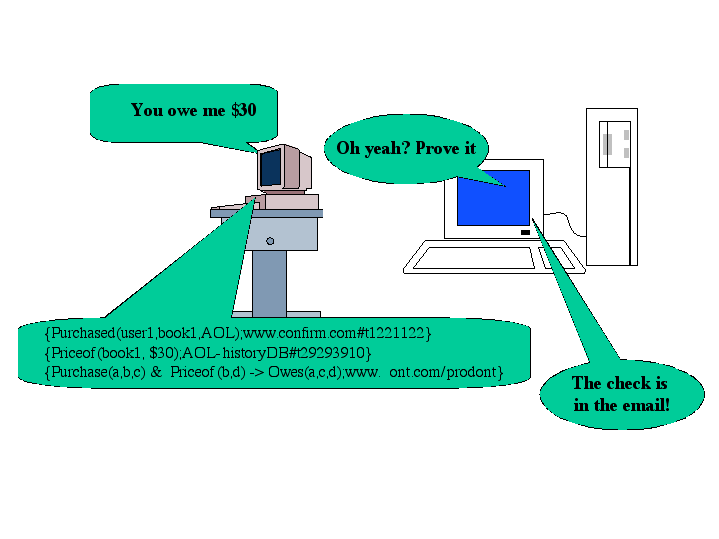
Figure 4: Agents exchanging simple proofs
Such service logics could be used for many other purposes as well. For example, (Subrahmanian et al., 2000) discusses the use of deontic logics and agent programs for multiagent systems. These logics, tied to the appropriate service descriptions, can represent what an agent can do and when it may (or may not) do so. Logical descriptions of services could also be used for automated matchmaking and brokering, for the planning of a set of services that together achieve a user’s goal, and for other capabilities currently discussed, but not yet implemented "in the wild," for multi-agent systems.
Agent-to-Agent Communication
Of course, having pages, service descriptions, and agent programs that are linked to many ontologies, which may themselves include links to still other ontologies and so on, raises some compelling issues. Figure 5 shows a representation of a small piece of this ontological web to help show a couple of examples. The small boxes represent agents or other web resources that use the terms in web ontologies represented by the larger boxes. The arrows represent any mechanism that provides a mapping (full or partial) from one ontology into another. This can be as simple as "inclusion" of terms or as complex as some sort of ad hoc mapping program that simply reads in terms from one and spits out terms of another. The figure shows one DAG (directed acyclic graph) that could be "lifted" from the much larger web of ontologies (and which may include cycles).
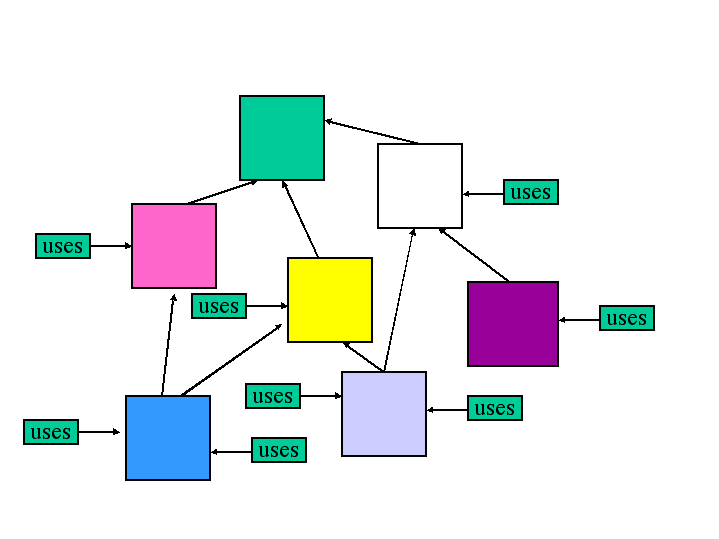
Figure 5: Mappings between agents and the ontologies they use.
Assuming agents are communicating with each other (using the terms in these ontologies for the content terms), then it is clear that if they point at the same set of terms, then it is relatively straightforward for them to communicate. By linking to these ontologies the agents commit to using the terms consistently with the usage mandated in that ontology. Thus, if the ontology specifies that a particular class has a particular property and that there is some restriction on that property, then each agent can assume that the other has legal values for that property maintaining that restriction, etc.
More interestingly, one can see that it is possible that if the agents are not using the same ontologies they may still be able to communicate. If all mappings were perfect, then obviously any agent could still communicate with any other by finding a common ontology they could both map into. More likely, however, is that the ontologies are only partially or imperfectly mapped. This would happen, for example, in the case presented earlier in this paper on Mary’s pet shop site. When Mary defined her site’s ontology as linking back to the zoo’s animal ontology, she changed some definitions, but left others untouched. Those terms that were not modified, or were modified in certain restricted ways, could be mapped, even if others couldn’t. Thus, those ontologies made by combination and extension of others could, in principle, be partially mapped without too much trouble.
With this in mind, let’s once again consider the DAG represented in Figure 5. It should be clear that many of these agents could be able to find at least some terms that they could share with others. For some, such as the agents pointing at ontologies C and E, the terms they share may be some sort of subset – in this case the agent at E may be able to use only some of the terms in C (those which were not significantly changed when E was defined). Other agents, such as the ones pointing at F and G, might share partial terms from another ontology which they both changed (D in this case). Looking at Figure 4 we can see that all of the agents may share some terms with all of the others, although it may take several mappings to do so (and thus there may be very few common terms, if any, in some cases).
The above discussion is purposely vague with respect to what these mappings are and how they work. In the case of certain kinds of restricted mappings there may be interesting formal results that can be obtained. For example if all mappings are "inclusion" links (that is, the lower ontology includes all the terms from the upper one in Figure 5) and a rooted DAG can be found among a set of agents, then all those agents can be guaranteed to share some terms with all others (although in the worst case some may only share the terms from the uppermost ontology). If the mappings are more ad hoc, for example they may be some sort of procedural maps defined by hand, we may lose provable properties, but gain in power or efficiency.
The research issues inherent in such ontology mappings are quite interesting and challenging. For example, two agents that communicate often might want to have maximal mappings or even a merged ontology. Two agents that are simply sending a single message (such as the invocation of an online service as described above) may simply want some sort of quick, "on the fly" translation limited just to the terms in a particular message. Another approach may be to use very large ontologies, such as CYC (Lenat and Guha, 1990) to actually infer mapping terms between agents in other ontologies. The possibilities are endless, and are another exciting challenge for researchers interested in bringing agents to the semantic web.
Summary
This paper was not intended as a comprehensive technical tome aimed at describing an archival piece of work. Rather, I hope that I have convinced the reader several strands of research in the fields of AI, World Wide Web languages, and multi-agent systems can be brought together in exciting and interesting ways. Many of the challenges inherent in bringing communicating multi-agent systems to the web require ontologies of the type being developed in DARPA’s DAML program and other efforts. More importantly, the integration of agent technology and ontologies may make significant impact on the use of web services and the ability to extend programs to more efficiently perform tasks for users with less human intervention. Unifying these research areas and bringing to fruition a web teeming with complex, "intelligent" agents is both possible and practical, although a number of research challenges still remain. The pieces are coming together, and thus, the semantic web of agents is no longer a science fiction future. It is a practical application on which to focus current efforts.
Acknowledgements
This paper has benefited from reviews by a wide number of early readers. Oliver Selfridge gave the most comprehensive, including the addition of several paragraphs of text. I am also indebted to David Ackley, Tim Berners-Lee, Dan Brickley, Dan Connolly, Jeff Heflin, George Cybenko, Ora Lassila, Deborah McGuinness, Sheila McIlraith, Frank van Harmelen, Dieter Fenstel and many participants in the CoABS, DAML, and TASK DARPA initiatives who gave me comments on earlier drafts. I also am indebted to an anonymous reviewer who, shall we say, wasn't impressed by an earlier version, and demanded copious changes. I made many of these, and it improved the paper greatly.
References:
Andrew W. Appel and Edward W. Felten, Proof-Carrying Authentication, 6th ACM Conference on Computer and Communications Security, November 1999.
P. Clark and B. Porter (1997), Building Concept Representations from Reusable Components. , Proceedings of the Fourteenth National Conference on Artificial Intelligence (AAAI-1997), ). AAAI/MIT Press, Menlo Park, CA.
EbXML (2000), Electronic Business Infrastructure, UN/CEFACT and OASIS, documentation available at
http://www.ebXML.org/ESPEAK (2000), Hewlett Packard’s Service Framework Specification, documents available at
http://www.e-speak.hp.com/Dieter Fensel, V. Richard Benjamins, Stefan Decker, Mauro Gaspari, Rix Groenboom, William Grosso, Mark Musen, Enrico Motta, Enric Plaza, Guus Schreiber, Rudi Studer, and Bob Wielinga: The Component Model of UPML in a Nutshell. In WWW Proceedings of the 1st Working IFIP Conference on Software Architecture, (WICSA1), San Antonio, Texas, USA, February 1999.
D. Fensel, I. Horrocks, F. Van Harmelen, S. Decker , M. Erdmann and M. Klein, OIL in a nutshell, in R. Dieng(ed), Lecture Notes in Artificial Intelligence # 1937 --Proceedings of the 12th European Workshop on Knowledge Acquisition, Modeling, and Management (EKAW-00), Springer-Verlag, 2000
M. Genesereth, R. Fikes, et.al. , Knowledge Interchange Format Version 3.0 Reference Manual,
http://logic.stanford.edu/kif/Hypertext/kif-manual.html.T. R. Gruber. A translation approach to portable ontologies. Knowledge Acquisition, 5(2):199-220, 1993.
Jeff Heflin and James Hendler (2000), Dynamic Ontologies on the Web, Proceedings of the Seventeenth National Conference on Artificial Intelligence (AAAI-2000). AAAI/MIT Press, Menlo Park, CA.
Jeff Heflin, James Hendler, and Sean Luke (1998), Reading Between the Lines: Using SHOE to Discover Implicit Knowledge from the Web, Proceedings AAAI-98 Workshop on AI and Information Integration.
Hendler, J (1999), "Is there an intelligent agent in your future," Nature, Web Matters, March 11. (available from http://www.nature.com/nature/webmatters/)
Junger, S. (1997), The Perfect Storm: A True Story of Men Against The Sea, W.W. Norton and Co. London, UK.
Laks V.S. Lakshmanan, Fereidoon Sadri, and Iyer N. Subramanian (1996), A Declarative Approach to Querying and Retsructuring the World-Wide-Web. Post-ICDE Workshop on Research Issues in Data Engineering (RIDE'96). New Orleans, February 1996.
Lenat, D. and Guha, R. Building large knowledge-based systems: Representation and Inference in the CYC project, Addison Wesley, 1990.
McIlraith, S. (forthcoming), "Modeling and Programming Devices and Web Agents'', Proceedings of the NASA Goddard Workshop on Formal Approaches to Agent-Based Systems, Lecture Notes in Computer Science, Springer-Verlag. To appear, 2000.
V. S. Subrahmanian, Piero Bonatti, Jürgen Dix, Thomas Eiter, Sarit Kraus, Fatma Ozcan, and Robert Ross (2000), Heterogeneous Agent Systems, MIT Press.
UDDI (2000), Universal Description, Discovery and Integration of Business for the Web, Executive and Technical White Papers available at
http://www.uddi.org.F. Zini and L. Sterling (1999), Designing Ontologies for Agents. In M. C. Meo and M. Vilares-Ferro, editors, Proc. of Appia-Gulp-Prode'99: Joint Conference on Declarative Programming, pages 29-42, L'Aquila, Italy, September 1999.