Linked Lists II
Advanced Programming---CSCI-6090
In looking at the details of the Hewlett-Packard STL list
class source code, we've gone over the class data and function
members and some of the type definitions inside the class.
Now let's look at two other major features of this implementation:
- The iterator class definitions and typedefs that are nested
inside the list class. These are defined in file
listiter.h.
- The special storage management code in the
list_memory_manager class defined in file
memman.h.
List iterator types
Iterator types define a convenient and standardized means of
traversing the items in a sequence. STL requires that these
types present an interface with the same operators
one uses with ordinary C++ pointers; in particular, they
must define ++ as an operation for advancing to the next
position in a sequence and * for getting a reference to
the current position so it can be stored into or accessed.
We will now see exactly how this is done in the case of
iterators for traversing STL lists.
Class iterator
Here is the definition of the basic list iterator type,
slightly simplified:
class iterator {
protected:
link_type current;
public:
iterator() {}
bool operator==(const iterator& x) const {
return current == x.current;
}
bool operator!=(const iterator& x) const {
return current != x.current;
}
reference operator*() const { return current->data; }
iterator& operator++() { // prefix ++
current = current->next;
return *this;
}
iterator operator++(int) { // postfix ++
iterator tmp = *this;
++(*this);
return tmp;
}
iterator& operator--() { // prefix --
current = current->prev;
return *this;
}
iterator operator--(int) { // postfix --
iterator tmp = *this;
--(*this);
return tmp;
}
};
This class defines one data member,
link_type current;
Recall that link_type is defined in class list as
list_node*. Thus iterator objects are
represented by ordinary pointers, but instead of using
the predefined meanings of ++, *, etc.,
on these pointers, we define these operators on the iterator
objects differently.
The definition of * is
reference operator*() const { return current->data; }
where the return type reference is defined in class
list as T&. The operator thus returns a reference to
the data member of the list_node object to which
current points. We can use this reference to get the current
value from the data member in the node or to store a new value into
it. Consider, for example,
list<char> list1;
list1.push_back('a');
list<char>::iterator i = list1.begin();
// Now iterator i points to the list node containing 'a'
cout << *i;
*i = 'b';
cout << *i;
This prints
ab
There are two definitions of ++ on iterator objects:
iterator& operator++() { // prefix ++
current = current->next;
return *this;
}
iterator operator++(int) { // postfix ++
iterator tmp = *this;
++(*this);
return tmp;
}
The first of these functions is the one that is called when
++ is used as a prefix operator, and the second is one called
when ++ is used as a postfix operator. (The use of the
int parameter in the second definition is just an artificial
device in the language design to give the compiler a way to
distinguish the two definitions. In calls of these functions no
int argument is used; we just write ++i for the
prefix version or i++ for the postfix version.) In both
cases, the internal current pointer is advanced to the next
node in the list. With the prefix version, the iterator object
returned is the original one with its new internal pointer value. With
the postfix version, on the other hand, a copy is made of the original
iterator (*this), the original iterator's current pointer is
advanced (with ++(*this), which is a call of the prefix
version), and the copy is returned. This semantics for the return
values is consistent with the way prefix and postfix ++ are
defined on ordinary pointers.
Exercise: Draw before and after diagrams of a list and two
iterators i and j both pointing to the same node in
the list, showing the difference between p = ++i and q =
j++, where p and q are two other iterators.
Exercise: Note that in the prefix version the return type is
iterator& but in the postfix version the return type is
just iterator. Explain why these are the most appropriate
return types. Hint: assume we want
++(++i);
to advance i twice. Would
++(i++);
advance i twice? Would it if postfix ++ returned a reference?
For -- there are again two definitions, set up exactly
analogously to ++, but using the list node's prev
pointer instead of next.
The actual definition of class iterator in class
list has a few more flourishes at its beginning:
class const_iterator; // incomplete definition, for use in friend decl.
class iterator : public std::iterator<bidirectional_iterator_tag,
value_type, difference_type, pointer, reference> {
friend class list<T>;
friend class const_iterator;
protected:
link_type current;
iterator(link_type x) : current(x) {}
public:
... rest is the same as discussed above, with one exception
... discussed below
};
Here the iterator class definition is preceded by an incomplete
definition (that's exactly what it's called in C++ terminology):
class const_iterator;
The actual, complete definition of class const_iterator
follows that of class iterator. The incomplete definition is
given so that class const_iterator can be declared a friend
of class iterator, which is necessary because one of
const_iterator's constructors needs access to the current
internal data member of iterator.
We also see that class iterator is derived from struct
iterator:
class iterator : public std::iterator<bidirectional_iterator_tag,
value_type, difference_type, pointer, reference> {
...
};
The latter class is defined in the standard header iterator
as follows:
template <class _Category, class _Tp, class _Distance = ptrdiff_t,
class _Pointer = _Tp*, class _Reference = _Tp&>
struct iterator {
typedef _Category iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Pointer pointer;
typedef _Reference reference;
};
};
It is used as a kind of "hook" to hang information about the iterator
type so that it can be extracted for use in other declarations where
necessary. For example, the information is extracted by the
the reverse_iterator struct template used in adapting
reverse iterator types from the normal list iterator types.
Finally, note that there is one protected member function, a
constructor for converting a link_type pointer into an
iterator.
iterator(link_type x) : current(x) {}
Such a constructor is needed in a few places in class
list. Even though it is protected in class iterator,
class list has access to it because class iterator
grants friendship to class list.
Class const_iterator
The definition of this class almost identical to that of class
iterator. The main difference is that operator * in class
const_iterator returns a const_reference (const
T&) instead of a reference (T&):
typename const_iterator::reference
operator*() const { return current->data; }
This means that a list item pointed to by a const_iterator
cannot be changed by assignment (or any other means); the
const in const T& prevents any attempt at using
*i as an lvalue.
list<char> list1;
list1.push_back('a');
list<char>::const_iterator i = list1.begin();
// Now iterator i points to the list node containing 'a'
cout << *i;
*i = 'b'; // COMPILATION ERROR
cout << *i;
Exercise: Another way to prevent the use of *i as an lvalue
would be to define
T operator*() const { return current->data; }
so that a copy of the data member is returned instead of a reference.
What would be the disadvantage of this method in comparison with
returning const T&?
There is one function defined by class const_iterator with no
analog in class iterator, namely the constructor
const_iterator(const iterator& x) : current(x.current) {}
This converts an iterator into a const_iterator.
Thus for example if we have an iterator i we can use
it to initialize a const_iterator j for use in computations
where we do not need to change the values to which the iterator points
and we want to be prevented from accidentally doing so.
Exercise: Explain why there is no corresponding constructor in
class iterator for converting a const_iterator into
an iterator.
Exercise: Where in the definition of class
const_iterator is there any need for the friendship
privileges granted it by class iterator?
Exercise (advanced): The definitions of class iterator
and class const_iterator are so similar that one would like,
if possible, to find a way of avoiding the code repetition. Discuss
the pros and cons of using class inheritance and virtual functions to
solve this problem.
Reverse Iterators
There are two other iterator types defined within class list,
namely reverse_iterator and const_reverse_iterator.
These types provide for traversal of lists in the opposite of the
normal direction, by exchanging the roles of ++ and --.
When such iterators are combined with STL generic algorithms, the effect
is to make the algorithms "see the sequence in reverse".
Consider, for example, the generic find algorithm, which
normally returns the first occurrence of a value in a traversal
starting from the beginning of the sequence. When combined with
reverse iterators it finds the first occurrence in a backward
traversal starting from the end of the sequence, which would be the
last occurrence in a normal traversal from the beginning.
Another example, using the generic accumulate algorithm, is
discussed in Musser & Saini, Section 2.5 and Example
2-13.
Instead of nested class definitions, like those for iterator
and const_iterator, the reverse iterator types are defined
by typedefs that use one STL's iterator adaptors,
reverse_iterator:
// Define reverse iterators using reverse iterator adaptors:
typedef std::reverse_iterator<iterator>
reverse_iterator;
typedef std::reverse_iterator<const_iterator>
const_reverse_iterator;
The way the reverse_iterator adaptor is defined is a bit
complicated and we won't go into it here, but the basic idea of the
class is simple: it redefines ++ as -- and
-- as ++.
Special list memory management
Recall that we said that special storage management techniques are
used in the Hewlett-Packard implementation of STL lists so that
new and delete do not have to be called for each
node. The problem with calling new and delete too
frequently is that they are very general run-time facilities and are
not optimized for the rather special usage in the list class. (They
have to be able to respond to requests to allocate or deallocate
blocks of any size, but all of our list nodes are of a fixed size and
their allocation can be handled with much simpler and faster methods
than are necessary for the general allocation problem.)
As a user of STL lists you don't have to worry about this issue,
because it's all done automatically. Nevertheless it is instructive to see
how it is done, for at least two reasons:
- The way storage is obtained and released involves additional useful list
processing techniques.
- The way storage is initialized and de-initialized sheds light on
the role of the constructor and destructor members of C++ classes. It
turns out that one needs a finer degree of control over initialization
and de-initialization than is normally supplied by constructors and
destructors, but (as usual) C++ does provide the necessary degree of
control.
Overview
The basic idea of storage management for list processing is to maintain a
"free storage list" (or "free list"), containing nodes that are not
in use by any application-level list. When a node is needed for
insertion into an application-level list, one can be taken off of
the free list. When a node is deleted from an application-level list,
it can be inserted into the free list.
How is the free list created in the first place? One way is to
allocate a array, or block, of N nodes and step through them
one by one, linking each to the one that follows it (or the one that
precedes it), forming a linked list of N nodes. Later, as
application-level lists are formed and destroyed, each node in the
block belongs either to one of these lists or to the free list.
A more clever variation is to do this traversal only as required, by
maintaining a boundary marker between nodes that have been linked and
ones that haven't. Initially the boundary is at the beginning of the
block, but as nodes are needed it is moved forward one node at a time.
To the left of the boundary, each node belongs either
to one of the application-level lists or to the free list; and to
the right of the boundary, the nodes have not yet been linked.
Whenever a node is needed for insertion into an application-level list
and the free list is empty, the boundary is moved one position to the
right, making another node available for linking.
Here is a diagram of the second scheme in progress, in which
next_avail marks the boundary and free_list points
to the beginning of the list of free nodes (it would be NULL
if all nodes were in use):
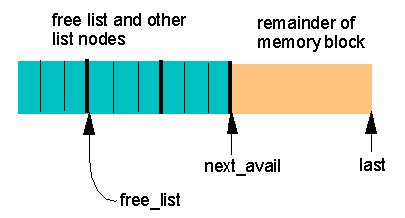
With either scheme, if we use up all N nodes in
application-level lists, we somehow have to create free nodes in some
other block of storage. One textbook suggests using an
"array-doubling" scheme much like STL uses when it runs out of space
in a vector. But array-doubling involves the overhead of copying the
currently active data into another block of memory, and it is really
only required if one needs all storage for the data structure
in one block of contiguous memory to
enable random-access. For lists, random-access isn't possible anyway,
and we can avoid the overhead of copying: when we run out of storage
in one N-element block, we just allocate another one. The
new block's position relative to the existing one doesn't matter; a
list can have nodes in both blocks because they are connected by links
anyway.
Obviously, we can keep doing this, allocating as many blocks of size
N as we need (or until we run out of storage completely). These
blocks can be obtained as needed using a new expression, in the normal
way. (Or almost normal, see below.) All we
have to be careful about is to keep track of where all these blocks
are, so that we can later clean up all the storage, when all need for
it is past. How do we do this? By keeping track of the locations
of the memory blocks in a linked list!
Here is a diagram of how the blocks of storage for lists are organized:
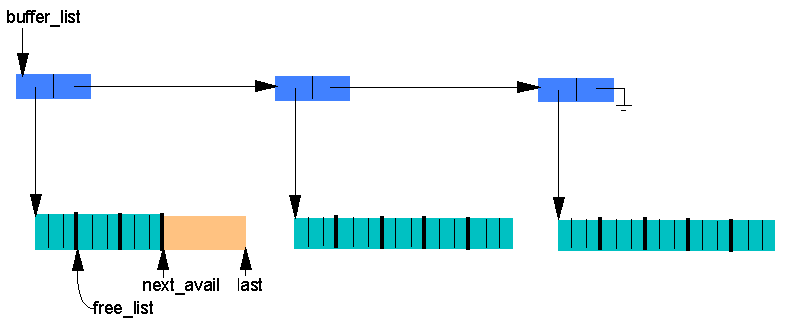
Exercise. Where do we get the nodes for the top-level list of block
locations? (Try to answer this before looking at the code details,
discussed next.)
Coding details
The code for implementing this overall scheme is shorter than the
explanation.
Block allocation function
First, there is a function block_allocate for
allocating the blocks of memory. Basically this function is just a
call of the global operator new to get a block of storage big enough
to hold a given number of items of type T:
template <class T>
inline T* block_allocate(ptrdiff_t size, T*) {
return (T*)(::operator new((size_t)(size * sizeof(T))));
}
This looks like a rather complicated way of doing things, compared to
the normal way of using new to get an array of size
elements of type T:
new T[size];
The problem with this would be that the elements of the array would
all be initialized using the default constructor of type T.
What we need instead at this point is a block of "raw" (uninitialized)
memory. We will call the type T constructor later, when
part of the memory is made into a node to be inserted in some list.
The reason for this strategy is efficiency:
If we initialized the entire block with N calls to the
default constructor, when we later use one node in a list we would
have to use the T assignment operator to put the value we
really want in the node. The effort the default constructor went to to
initialize the storage would be wasted. Furthermore, when we return
the node to the available space list we would have to do another
assignment to replace the current value with the default constructor
value (in order to release as much storage as possible).
Since we delay initializing the storage until we need it, we have to
make sure we do initialize it properly when we do use it for a node in an
application-level list. Let's now look back at how that was done in
the insert member function in class list:
template <class T>
inline list<T>::iterator list<T>::insert(iterator position, const T& x) {
link_type tmp = manager.get_node();
new (&(tmp->data)) T(x);
tmp->next = position.current;
tmp->prev = (position.current)->prev;
(position.current)->prev->next = tmp;
(position.current)->prev = tmp;
++length;
return tmp;
}
We said earlier that we could think of the second line of the
body of this function as though it were written
tmp->data = x;
but in fact the actual meaning is different. The expression
&(tmp->data)) in the new expression is called a
new-placement, because it tells the location of already
allocated storage. This kind of new expression does not
allocate any storage; it just does a constructor call, T(x),
to initialize the storage to which the new-placement points.
Thus raw storage is converted into a properly initialized type
T object.
Exercise. Consider the case in which T is itself is a
list instance, as in
list< list<int> > list1;
What is the difference in this case between
tmp->data = x;
and
new (&(tmp->data)) list<int>(x);
List memory manager class
The rest of the allocation scheme is implemented in class
list_memory_manager. This class begins with a
struct, list_memory_manager, and some types and data
members for implementing the list of buffers (blocks) of
list_nodes:
template <class list_node>
class list_memory_manager {
typedef list_node* link_type;
struct list_node_buffer {
list_node_buffer* next_buffer;
list_node* buffer;
};
typedef list_node_buffer* buffer_pointer;
buffer_pointer buffer_list;
link_type free_list;
link_type next_avail;
link_type last;
ptrdiff_t buffer_size() { return 1024; }
...
There is also a private member function, add_new_buffer,
that takes care of allocating a new buffer when put_node
needs one. This is where block_allocate is called.
...
void add_new_buffer() {
buffer_pointer tmp = new list_node_buffer;
tmp->buffer = block_allocate(buffer_size(), (list_node*)0);
tmp->next_buffer = buffer_list;
buffer_list = tmp;
next_avail = buffer_list->buffer;
last = next_avail + buffer_size();
}
...
There is a corresponding function deallocate_buffers, which
is public because the list destructor needs to call it to get rid
of all of the buffers when the last list has been destroyed.
...
public:
void deallocate_buffers() {
while (buffer_list) {
buffer_pointer tmp = buffer_list;
buffer_list = (buffer_pointer)(buffer_list->next_buffer);
delete (tmp->buffer);
delete tmp;
}
free_list = 0;
next_avail = 0;
last = 0;
}
...
Finally, we have the main allocation member functions used in
the list class:
...
link_type get_node() {
link_type tmp = free_list;
if (free_list != NULL) {
free_list = (link_type)(free_list->next);
return tmp;
}
if (next_avail == last)
add_new_buffer();
return next_avail++;
}
void put_node(link_type p) {
p->next = free_list;
free_list = p;
}
};
Exercise. Hand execute a few calls to get_node,
considering the cases where the current buffer (block) does or does
not have space left in it.
Exercise. Why doesn't put_node ever deallocate a buffer?
This completes our discussion of the STL List class.