Lecture 15 — Dictionaries, Part 1¶
Overview¶
- More on IMDB
- Dictionaries and dictionary operations
- Solutions to the problem of counting the movies each individual is involved in
- Other applications
How Many Movies is Each Person Involved In?¶
- Goals:
- Count movies for each person.
- Who is the busiest?
- What movies do two people have in common?
- Best solved with the notion of a dictionary, but we’ll at least consider how to use a list.
List-Based Solution — Straightforward Version¶
Core data structure is a list of two-item lists, each giving a person’s name and the count of movies.
For example, after reading the first seven lines of our shortened hanks.txt file, we would have the list
[ ["Hanks, Jim", 3], ["Hanks, Colin", 1], ["Hanks, Bethan", 1], ["Hanks, Tom", 2] ]
Just like our solution from the sets lectures, we can start from the following code:
imdb_file = raw_input("Enter the name of the IMDB file ==> ").strip() count_list = [] for line in open(imdb_file): words = line.strip().split('|') name = words[0].strip()
Like our list solution for finding all IMDB people, this solution is VERY slow — once again
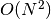 (“order of N squared”).
(“order of N squared”).
List-Based Solution — Faster Version Based on Sorting¶
- Append each name to the end of the list without checking if it is already there.
- After reading all of the movies, sort the entire resulting list
- As a result, all instances of each name will now be next to each other.
- Go back through the list, counting the occurrence of each name
- This solution will be much faster than the first, but it is also much more involved to write than the one we are about to write using dictionaries
Introduction to Dictionaries¶
Association between “keys” (like words in an English dictionary) and “values” (like definitions in an English dictionary). The values can be anything.
Examples:
>>> heights = dict() # initialization 1 >>> heights = {} # initialization 2, only one or the other is necessary >>> heights['belgian horse'] = 162.6 >>> heights['indian elephant'] = 280.0 >>> heights['tiger'] = 91.0 >>> heights['lion'] = 97.0 >>> heights {'tiger': 91.0, 'belgian horse': 162.6, 'indian elephant': 280.0, 'lion': 97.0} >>> 'tiger' in heights True >>> 'giraffe' in heights False >>> heights.keys() ['tiger', 'belgian horse', 'indian elephant', 'lion']
Details:
- Two initializations; either would work.
- Syntax is very much like the subscripting syntax for lists, except dictionary subscripting/indexing uses keys instead of integers!
- The keys, in this example, are animal species (or subspecies) names; the values are floats.
- The in method tests only for the presence of the key, like looking up a word in the dictionary without checking its definition.
- The keys are NOT ordered.
Just as in sets, the implementation uses hashing of keys.
- Conceptually, sets are dictionaries without values.
Exercise¶
Hand-write or type each of the following:
Form a dictionary called countries that associates the population with each of the following countries:
- Algeria 37,100,000
- Canada 34,945,200
- Uganda 32,939,800
- Morocco 32,696,600
- Sudan 30,894,000
Assuming that all of this has been done, what is the output of the following, when typed into the Python interpreter?
>>> print len(countries) >>> print countries >>> print countries.keys() >>> print sorted(countries.keys()) # can you guess what this does?
Back to Our IMDB Problem¶
Even though our coverage of dictionaries has been brief, we already have enough tools to solve our problem of counting movies.
Once again we’ll use the following as a starting point
imdb_file = raw_input("Enter the name of the IMDB file ==> ").strip() count_list = [] for line in open(imdb_file): words = line.strip().split('|') name = words[0].strip()
We will impose an ordering on the output by sorting the keys.
We’ll test first on our smaller data set and then again later on our larger ones.
Key Types¶
- Thus far, the keys in our dictionary have been strings.
- Keys can be any “hashable” type — string, int, float, booleans.
- Lists, sets and other dictionaries can not be keys.
- Strings are by far the most common key type
- We will see an example of integers as the key type by the end of these notes.
- Float and boolean are general poor choices. Can you think why?
Value Types¶
So far, the values in our dictionaries have been integers and floats.
But, any type can be the values
- boolean
- int
- float
- string
- list
- tuple
- set
- other dictionaries
Here is an example using our IMDB code and a set:
>>> people = dict() >>> people['Hanks, Tom'] = set() >>> people['Hanks, Tom'].add('Big') >>> people['Hanks, Tom'].add('Splash') >>> people['Hanks, Tom'].add('Forest Gump') >>> print people['Hanks, Tom'] set(['Big', 'Splash', 'Forest Gump'])
Here is another example where we store the continent and the population for a country instead of just the population:
countries.clear() countries['Algeria'] = (37100000, 'Africa') countries['Canada'] = (34945200, 'North America' ) countries['Uganda'] = (32939800, 'Africa') countries['Morocco'] = (32696600, 'Africa') countries['Sudan'] = (30894000, 'Africa')
We access the values in the entries using two consecutive subscripts. For example,
name = "Canada" print "The population of %s is %d" %(name, countries[name][0]) print "It is in the continent of", countries[name][1]
Removing Values: Sets and Dictionaries¶
- For a set:
- discard removes the specified element, and does nothing if it is not there
- remove removes the specified element, but fails (throwing an exception) if it is not there
- For a dictionary, it is the del function.
- For both sets and dictionaries, the clear method empties the container.
- We will look at toy examples in class
Other Dictionary Methods¶
- The following dictionary methods are useful, but not so much as the
ones we’ve discussed.
- get
- pop
- popitem
- update
- Use the help function in Python to figure out how to use them and to find other dictionary methods.
Exercises¶
- Write code to discover who is the busiest individual in the IMDB.
- Write a function that takes the IMDB dictionary — which associates strings representing names with integers representing the count of movies — and an integer representing a min_count, and removes all individuals from the dictionary involved in fewer than min_count movies.
Summary of Dictionaries¶
- Associate “keys” with “values”
- Feels like indexing, except we are using keys instead of integer indices.
- Makes counting and a number of other operations simple and fast.
- Keys can be any “hashable” value, usually strings, sometimes integers.
- Values can any type whatsoever.