SQL - Other Features#
Overview#
In this section, we will review triggers, views and indices as well as some more advanced features of SQL.
Triggers#
A trigger has:
a database event that must be true for the trigger to be activated
Example: insert of class
a condition that must be true for the trigger to be executed
Example: when the new tuple has code CSCI
a method of execution - for each row that is being changed (inserted/updated/deleted) - for each statement (for a given transaction)
a triggering time - BEFORE the triggering event makes the updates
executed before the triggering change is even executed (and recorded)
AFTER the triggering event makes the updates
executed after the triggering change is recorded
INSTEAD OF the triggering event
a statement body:
a procedure that contains possibly multiple statements
Triggers become part of the transaction that triggered them.
Trigger access to changes#
For each update that changes a database, the tuple before and after the change can be accessed in a trigger - OLD: the tuple before an update - NEW: the tuple after the update
Inserts have no OLD, deletes have no NEW:
CREATE TRIGGER fix_favorites AFTER INSERT OR UPDATE OF results REFERENCING NEW ROW AS newt FOR EACH ROW WHEN (newt.result = 'star baker') DELETE FROM favorites WHERE baker = NEW.baker AND episodeid = NEW.episodeid ;
Postgresql syntax is a bit different for triggers. Define first a function that returns a trigger, then define a trigger.:
CREATE FUNCTION fix_favorites () RETURNS trigger AS $$ BEGIN IF NEW.result = 'star baker' THEN DELETE FROM favorites WHERE baker = NEW.baker AND episodeid = NEW.episodeid ; END IF ; RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER fix_favorites AFTER INSERT OR UPDATE ON results FOR EACH ROW EXECUTE FUNCTION fix_favorites(); CREATE FUNCTION fix_baker () RETURNS trigger AS $$ BEGIN NEW.baker = initcap(trim(NEW.baker)); RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER fix_baker BEFORE INSERT OR UPDATE ON bakers FOR EACH ROW EXECUTE FUNCTION fix_baker();Triggers can be defined on tables or views.
Triggers can be executed for each row being changed or a the whole statement.
Views#
A view is a query.
Views can be anonymous
SELECT * FROM (SELECT baker, fullname, age FROM bakers WHERE baker not in (select baker from results where result = 'eliminated') ) as noteliminated WHERE noteliminated.age > 45;
The relation noteliminated above is an anonymous view (it is not known outside of this query).
This query is combined with the remaining query to find the optimal query plan.
For example, the above query after optimization may become:
SELECT baker , fullname , age FROM bakers WHERE age > 45 and baker not in (select baker from results where result = 'eliminated');
When to use anonymous views:
It is best to use an anonymous view if the query cannot be written without it or it provides a savings that is missed by the optimizer.
Otherwise, the optimizer may miss some optimizations and rewritings of the query when views are used.
Views (not anonymous)#
Views can also be given a name. This allows them to be used in many different queries:
CREATE VIEW noteliminated(baker, fullnamename, age) AS SELECT baker, fullname, age FROM bakers WHERE baker not in (select baker from results where result = 'eliminated');
Using views in queries#
Views can be used in any query as if they were a table.
Remember, views are just queries. No tuples are stored for them.
SELECT * FROM noteliminated WHERE age > 45 ;
When executing this query, the query processor first takes the query definition and replaces the query name with its definition. Then, the query is optimized.
Why use views?#
Creating views allows the system designer to customize the application code so that:
The functionality for different users can be built on top of views.
For example, faculty cannot access financial information of students and can only the information about the students who are currently taking a course from them.
Solution: Create a view for the students in a specific class which only includes the relevant attributes. The application code will be built on top of this view.
Views can also be used to insert/update/delete tuples instead of the table they are based on.
This builds on the philosophy of building functionality based on views.
However, this is only possible for a very restricted subset of views, called updatable views.
Updatable views are such that each tuple in the view maps to one and only one tuple in the table it is based on.
Using views to create functionality hides data complexity from developers.
Also, if the data model changes, the application code does not have to change as long as the new model can be mapped to the same view.
Why not use views?#
Writing a query using views may hide some optimizations from the database, creating sub optimal query plans.
Updatable views#
A view is updatable if:
It has only one table T in its from clause
It contains all attributes from T that cannot be null
It does not have any distinct, group by statements (one to one correspondence between a tuple in the view and a tuple in the table)
Example:
CREATE VIEW lt40(baker, fullnamename, age) AS SELECT baker, fullname, age FROM bakers WHERE age < 40; UPDATE lt40 SET age = 40 WHERE baker = 'Manon' ;
Note: lt40 does not store any tuples. This expression allows only those tuples of bakers that are accessible through view to be updated.
Furthermore, after the update, the resulting tuple may not even be in the view (unless the view is created with the CHECK OPTION):
UPDATE lt40 SET age = 40 WHERE baker = 'Manon' ;
Since now Manon is not younger than 40, she will not be returned by the view.
Indexing#
Views do not improve performance, sometimes they may even cause a loss of performance.
One way to improve performance is store (cache) the result of some queries in the database.
Indexes are exactly that, cached results of queries.
Example:
SELECT episodeid FROM technicals WHERE baker = 'Kim-Joy' and rank = 1;
Answering this query requires reading all of technicals relation from disk to find the matching tuples to return. Note that the matching tuples will be very few compared to all the tuples in the technicals table.
Cost Analysis#
Let us some basic cost analysis, but let us consider a much larger table X and a query that returns a few tuples as answer.
Suppose X is stored on disk in 100 disk pages. Then, answering this query requires reading all 100 disk pages.
Suppose instead we had an index that allowed us to find all the matching tuples.
Example: Index on Technicals (baker) for the above query, or a similar index for relation X
Then, answering this query will cost:
Finding the tuples from index, reading them from disk to fetch the grade.
Cost: at most 4-5 pages.
Indexing as views#
Indexes are just query results stored explicitly.
They are also stored on disk, but can be cheaper to use because:
They have fewer disk pages as they store only a subset of the attributes in the relation.
They are stored in a way to make it easy to find queries on specific values in the index (we will see how).
For now, we can assume that querying the index has a small cost as long as the query returns a few (1-3) tuples.
Index cost/benefit analysis#
Indices are good if
they reduce the cost of frequently asked queries
the reduction is considerable
Indices must be kept up to date when the tables change
Indices increase the cost insert/update/delete operations (at least one extra disk page access for each index created)
What are good indices#
A good index will reduce the total number of matching tuples to 1 or a few
Example: attributes in a key
An index on students(id) will greatly improve queries like
SELECT * FROM bakers WHERE baker = 'Rahul';
Almost all databases will create an index on the primary key.
If the underlying relation is sorted with respect to some attribute, then an index on that attribute will help performance.
Suppose, technicals tuples are sorted by baker and rank.
Create an index on Technicals(baker, rank)
Given the query:
- SELECT
episodeid
- FROM
technicals
- WHERE
baker = ‘Kim-Joy’ and rank = 1;
use the index to find the first tuple for baker ‘Kim-Joy’, and then scan the technicals relation starting from that point.
Access Structure#
A postgresql database cluster is organized into databases.
No data can be shared across databases.
Information in a database can be clustered into logical units called schema
Schema#
Create a schema with:
CREATE SCHEMA myschema;
Access/create tables in the schema with:
schema.table
To delete a schema and all the objects in it:
DROP SCHEMA myschema;
To create a schema owned by someone else:
CREATE SCHEMA schemaname AUTHORIZATION username;
Search path#
Whenever a table name is used, the database tries to find the correct instance
The search path is usually
first: $user: a schema with the same name as the current user
second: public: any information that is open to public, i.e. all users.
The search path can be changed by:
set search_path to ….
Security#
Postgresql allows the creation of roles
A role is like a user, but more general
A role with a login privilege is considered a user
A role can be given the right to create databases and/or create other roles.
A role with superuser privileges can bypass all security checks
Role creation and inheritance#
Inherit allows the role to inherit all the privileges given to that role.
CREATE ROLE joe LOGIN INHERIT; CREATE ROLE admin NOINHERIT; CREATE ROLE wheel NOINHERIT; GRANT admin TO joe; GRANT wheel TO admin;
Joe has privileges of admin upon login because user Joe inherits from its roles. However, admin does not have the privileges assigned to wheel because it does not inherit (it is not inherited).
As a role connects to the database, it has all the rights given to that role (login role). For other privileges that are not inherited, the user must explicitly set itself to that role:
SET ROLE admin ;
Database Objects#
All database objects (database, tables, indices, procedures, triggers, etc.) have an owner, the role that created them.
Owner has all the access rights on the objects they create.
Other roles can be given explicit privileges on these objects:
SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER, CREATE, CONNECT, TEMPORARY, EXECUTE, and USAGE.
Privileges#
SELECT, INSERT, DELETE, UPDATE are the privileges to query (select) and change the data of some other role.
Can be specific: SELECT(name)
REFERENCES is the right to refer to a relation in an integrity constraint
USAGE is the right to use a schema element in relations, assertions, etc.
TRIGGER is the right to define triggers.
UNDER is the right create subtypes
Grant option#
Users/roles can pass a privilege to another user/role is they have the grant option.
GRANT select ON users TO spock WITH GRANT OPTION
Only a role that has a grant option can grant the grant option to the others.
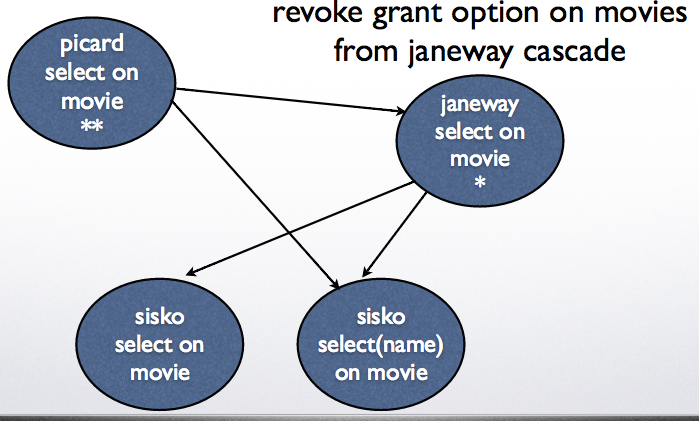
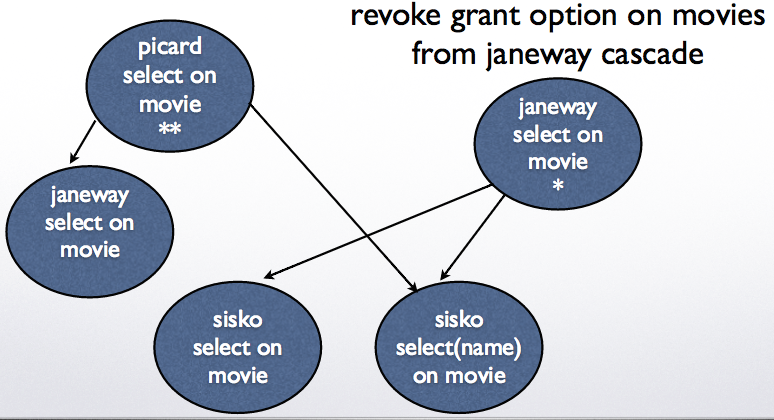
Grant diagrams#
Nodes represent a user and a privilege
Two different privileges of the same person should be put in two different nodes
If one privilege for a user is the more general version of another, they should both be included.
Example: select, select(name)
Each grant generates a path in the grant diagram
Nodes are marked by:
** for owners
* for users who have grant option
nothing for all other users

Adding privileges#
When a new privilege X is given from role A to role B
If there are no nodes for (A,X) and (B,X), then create them.
Add all the necessary links
Revoking privileges#
Revoke <privileges> on <database element> from <role list>
will remove the listed privileges.
Cascade: will remove any privileges that are granted only because of the removed privileges.
Restrict: will fail if the revoked privileges were passed on to other roles previously.
Delete any edges corresponding to the deleted privileges.
If there are any nodes not reachable from a double starred role, then they should be removed together with all the edges coming out of them.
Continue this process until all the nodes are reacheable from a doubly starred node.
Example 1: revoke select on movies from janeway cascade
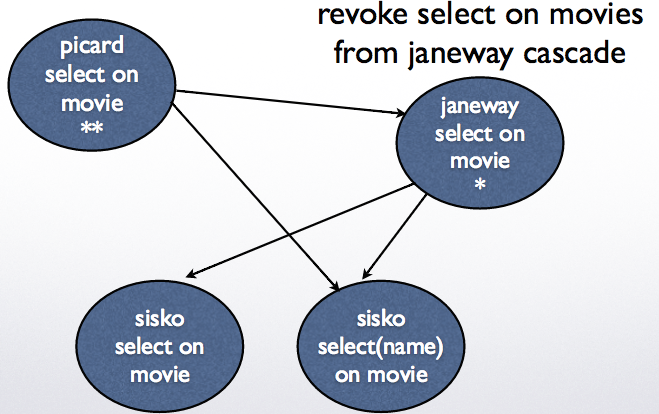
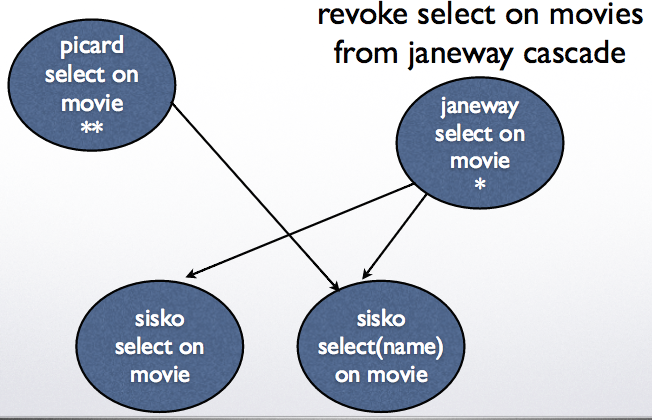
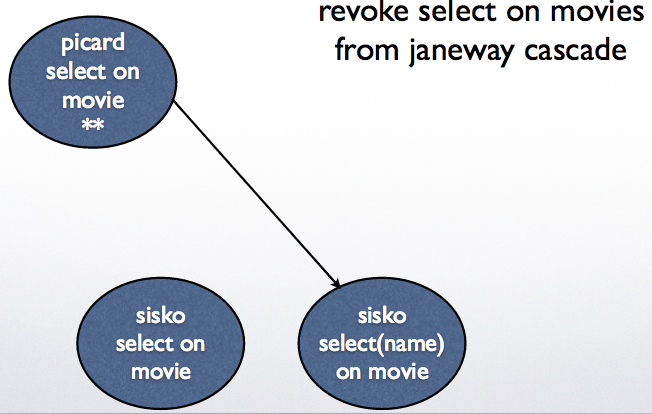
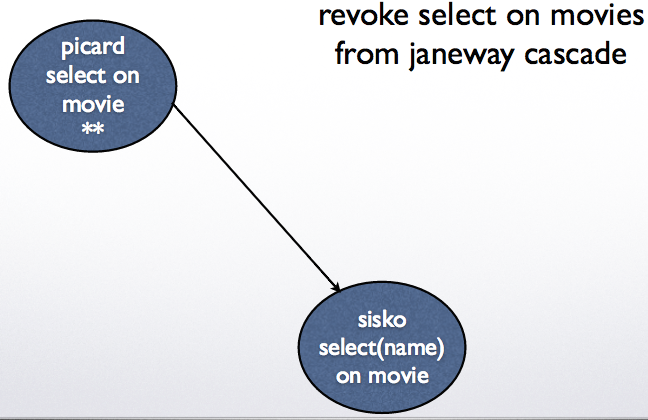
Example 2: revoke grant option on movies from janeway cascade

System Tables#
Information about the database are also stored in database tables that can be queried like any other
Examples:
pg_constraint: all constraints on tables
pg_user: all users that their access rights (can they create databases? are they superusers?)
pg_views: the name of the views, owner and tex
Case Statements in SELECT#
Not being able to write some simple if statement in SQL can be annoying. Well, you can actually.
SELECT a, CASE WHEN a=1 THEN 'one' WHEN a=2 THEN 'two' ELSE 'other' END FROM test; a | case ---+------- 1 | one 2 | two 3 | other
Group by extended#
Group by multiple groups
See
example database to be used.CREATE TABLE events ( name varchar(10) , day varchar(10) , time varchar(10) , price INT ) ; SELECT * FROM events; name | day | time | price ----------+-----+-------+------- sitting | M | 12:00 | 5 reading | W | 2:00 | 10 sleeping | M | 2:00 | 12 hopping | W | 12:00 | 8 jumping | M | 4:00 | 22 SELECT day , time , count(*) , sum(price) FROM events GROUP BY GROUPING SETS ((day),(time),()); day | time | count | sum -----+-------+-------+----- M | | 3 | 39 --grouped by day W | | 2 | 18 --grouped by day | | 5 | 57 --grouped by everything | 12:00 | 2 | 13 --grouped by time | 2:00 | 2 | 22 --grouped by time | 4:00 | 1 | 22 --grouped by time
Rollup does grouping in a hierarchical way, removing one attribute at a time
ROLLUP (day,time)
will first group by (day,time), then by (day) alone, then by everything.
Cube will do group by every combination:
CUBE (day, time)
will group by
(day,time) (day) (time) ()
Window Functions#
Window functions compute aggregates without a group by for a window of values.
SELECT name, day, time, sum(price) OVER (partition by day) FROM events ORDER BY day; name | day | time | sum ----------+-----+-------+----- sitting | M | 12:00 | 39 sleeping | M | 2:00 | 39 jumping | M | 4:00 | 39 reading | W | 2:00 | 18 hopping | W | 12:00 | 18
Group by with Filter#
Filter allows you to apply an aggregate to a subset of tuples in that group.
SELECT day
, sum(price) as total
, sum(price) filter (where price>10) as totalfiltered
FROM events
GROUP BY day;
day | total | totalfiltered
-----+-------+---------------
W | 18 |
M | 39 | 34
Recursive Queries#
Recursive queries use the basis query to build on itself:
See
example database to be used.SELECT * FROM parents ; parent | child ---------+--------- Dakota | Madison Madison | Ava Madison | Sophia Sophia | Noah Noah | Emma
Find all ancestral relations of degree 2 or higher:
WITH RECURSIVE ancestors(ancestor, child, degree) AS ( SELECT parent, child, 1 FROM parents UNION ALL SELECT a.ancestor, p.child, a.degree+1 FROM ancestors a, parents p WHERE a.child = p.parent ) SELECT ancestor, child, degree FROM ancestors WHERE degree>= 2; ancestor | child | degree ----------+--------+-------- Dakota | Sophia | 2 Dakota | Ava | 2 Madison | Noah | 2 Sophia | Emma | 2 Dakota | Noah | 3 Madison | Emma | 3 Dakota | Emma | 4